这是一篇圣母大学并行计算实验室(CCL Lab)17年发在ccgrid上的论文。论文主要工作是探讨如何将工作流管理系统(WMS)和容器资源管理平台结合,并且尽可能减少性能丢失和提高系统效率。文中使用的工作流系统是由该实验室开发的WMS——Makeflow,容器资源管理系统用到的是Mesos。文中提出了4种不同的结合方式,介绍了它们的优缺点和适用环境,并通过实验对比了这4中方式。
现状和问题
过去,工作流基本都是运行在实体机和虚拟机上(或者由它们搭建成的集群上),这会导致很多问题。比如在这个环境中能够跑通的工作流,在其他环境就跑不通。为了跑一个其他人的工作流,需要部署一个相同的环境,这样会耗费很大的时间和精力,而且不一定就能部署成功。
容器的出现解决了这些问题。
但是,这也产生了很多新的问题——如何将WMS和容器更好地结合?结合过程中遇到的问题该如何解决?容器管理平台那么多,该怎么选择……
本文中根据实际存在的 Challenge,提出了四种设计方案,并分析了它们的优缺点,对比了它们的实验效果。
本文用到的工具有三个:工作流管理系统 Makeflow,,容器资源管理系统 Mesos。
· Makeflow:
一个由圣母大学研发的工作流管理系统。它能够通过许多批处理系统来启动相同的工作流,例如HTCondor,Sun Grid Engine(SGE),Torque,SLURM,Amazon EC2 和 Work Queue(本文使用的)。
不管使用什么系统,MakeFlow 都希望它们按如下方式工作:对于工作流中的每个任务,为它们创建一个独立的沙箱(sandbox),将输入传输到沙箱中,执行任务并将输出从沙箱中移出。这种语义确保,除了输入依赖项以外的文件,其他文件都不会出现在执行环境中。Makeflow 会在依赖项OK后,执行任务。
· Work Queue:
一个由圣母大学研发的分布式系统 master-worker 执行引擎。该系统包括运行在用户端的一个 master 程,以及在用户指定数量的云上运行的 无数个 worker。作为执行引擎,Work Queue 可以跨多个集群、云和网格基础设施部署 worker。master 允许用户使用命令行创建任务。创建任务后,master 会将它们分配给可用的 worker。
worker 按如下方式执行任务:由 worker 创建一个缓存目录,master 会将 Input 文件存入这个目录。对于每个任务,worker 都会创建一个 sandbox,将 Input文件连接到sandbox中,在 sandbox 内执行任务,再将Outputs复制到缓存目录,然后 Outputs 将被传回 master。这种机制不仅允许每个任务具有独立的命名空间,而且允许不同的任务通过缓存目录共享数据。因此,多核机器上的单个 worker 可以同时执行多个任务。
· Mesos:
作为最流行的基于容器的资源管理系统之一,Meos 通过使用容器为需要的任务提供资源。一些容器调度程序采用了单级调度,如Kubsernes和Docker Swarm。与它们不同的是,Mesos采用了两级调度,它允许每个应用程序都有自己的调度框架。这个调度框架从Mesos Master接收提供给该应用程序的资源,并尝试为每个任务分配资源。
由于一个长任务可以占用许多资源,因此Mesos鼓励框架使用短任务。因为科学工作流通常包含可以短或长的异构任务,所以使用 Mesos 会对科学工作流调度有所限制。
Mesos 的主要架构如下:
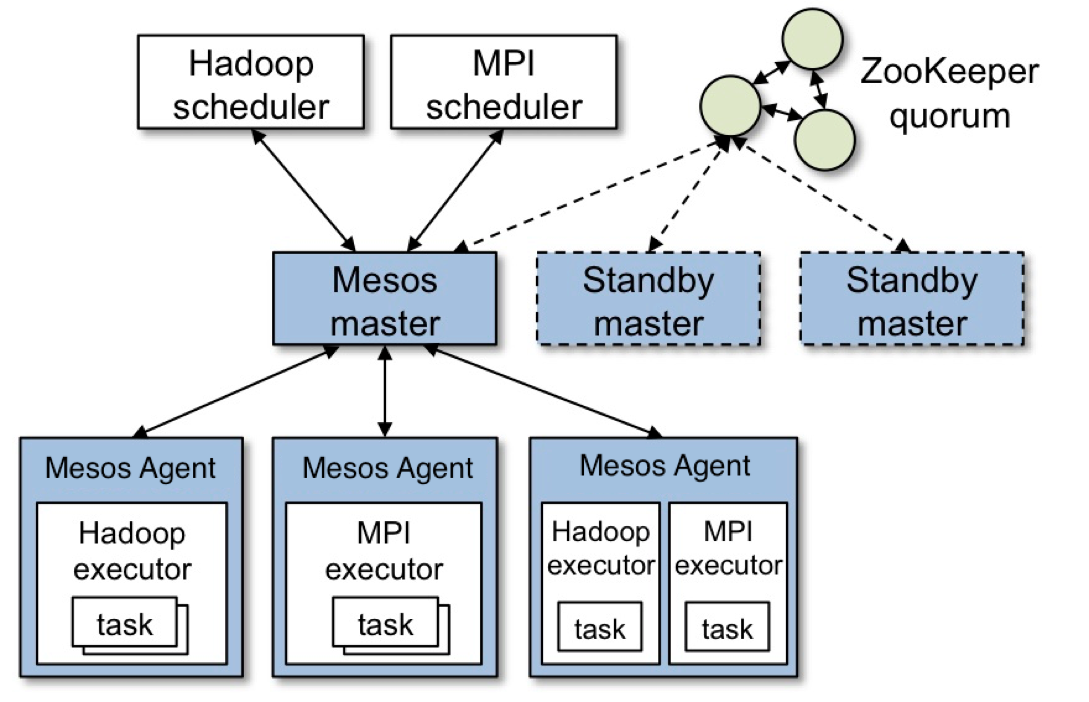
其两级调度可简单用下图概括:

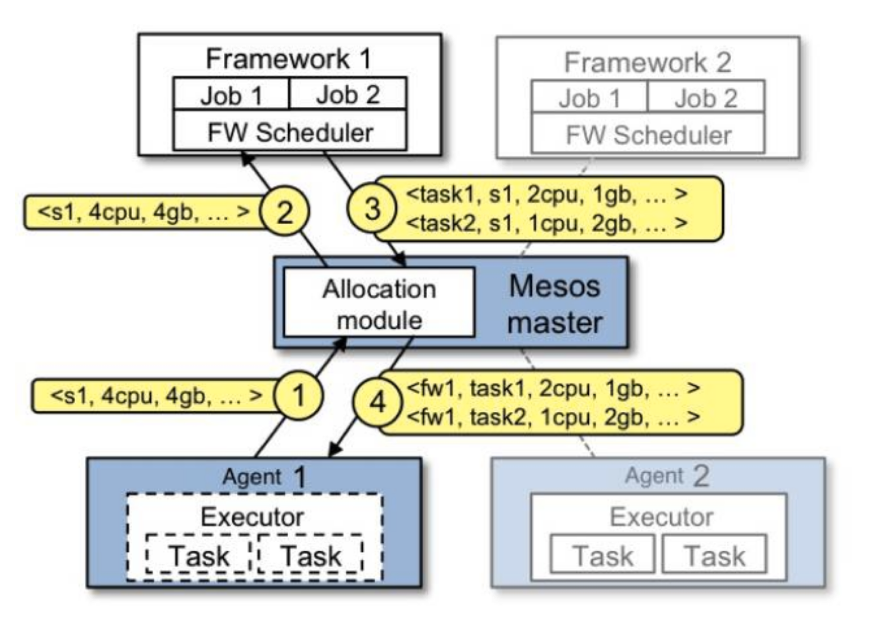
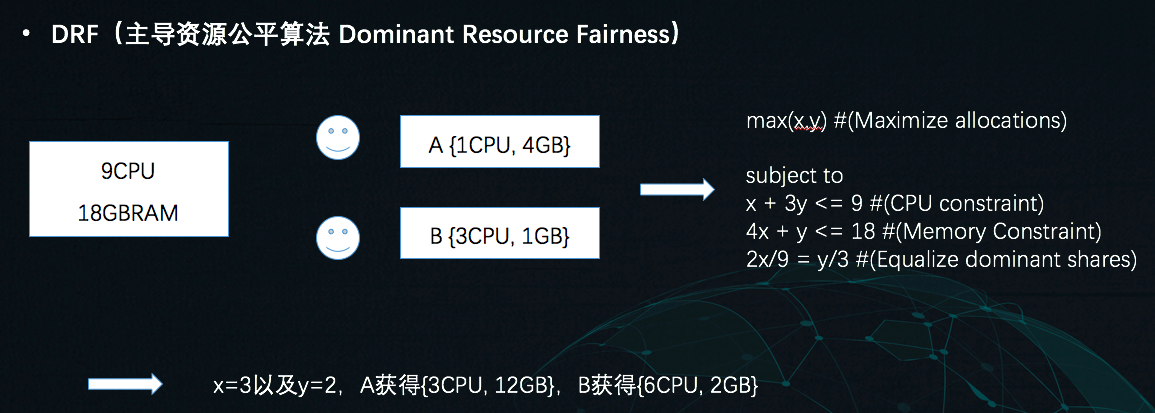
Mesos的第一级调度规则为「主导资源公平算法」(DRF)。这里用一个简单例子来描述。
假设全部可用资源为{9 cpu, 18G内存},有两个应用程序A和B,A中每个任务需要{1 cpu, 4G内存},B中每个任务需要{3 cpu, 1G内存}。那么对于A,它的主导资源是内存,B的主导资源是CPU。设A能调度的任务数为x,B为y,可以得到下图中的求解最优解的公式,从而得出x和y的值。
有关 Mesos 的调度,可以阅读这篇博客,深入了解。
方法和设计
挑战
- 前后端的task状态同步;
- 多个同阶段任务同时进行,读取数据,导致请求过多而网络拥塞;
- 长任务,占用资源,引发「饥饿」;
- “垃圾”回收的时间周期,如何确定?
- 如何提供精确的资源需求?
方案
· Makeflow 直接连接 Mesos:
- 带宽问题——在调度程序端实现了一个带有线程池的HTTP服务器。
- 长任务问题——有两个选择。一个是不在Mesos上启动长任务,而是在本地机器上使用Makeflow LOCAL模式运行任务;另一种方法是为短任务保留一定数量的资源,这需要用户扩展默认资源分配器。这里采用第二种。
- 垃圾回收问题——自定义执行程序,在调度程序检索到“符合条件”的中间数据后,删除它们。
- 精确资源需求——用户将任务分类为各种类别,并指定同一类别中任务的资源需求。
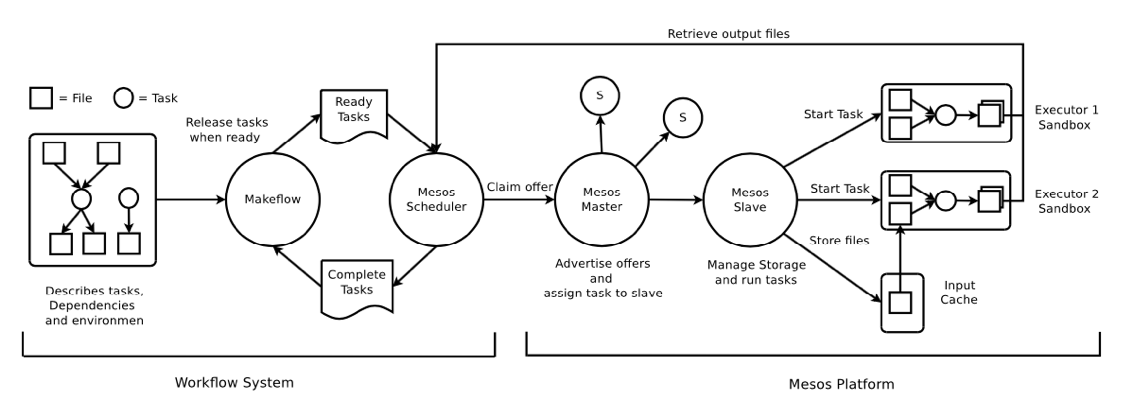
· Makeflow + Worker Queue + Mesos:
基于前一个方案作出的优化。
- 资源管理的优化——启动具有一定数量资源的Workers来限制每个工作流可用的资源量,并将备用资源分配给需要的工作流。
- 垃圾回收的优化——Work Queue可以删除Makeflow的所有中间数据,而不需要复杂的执行程序。
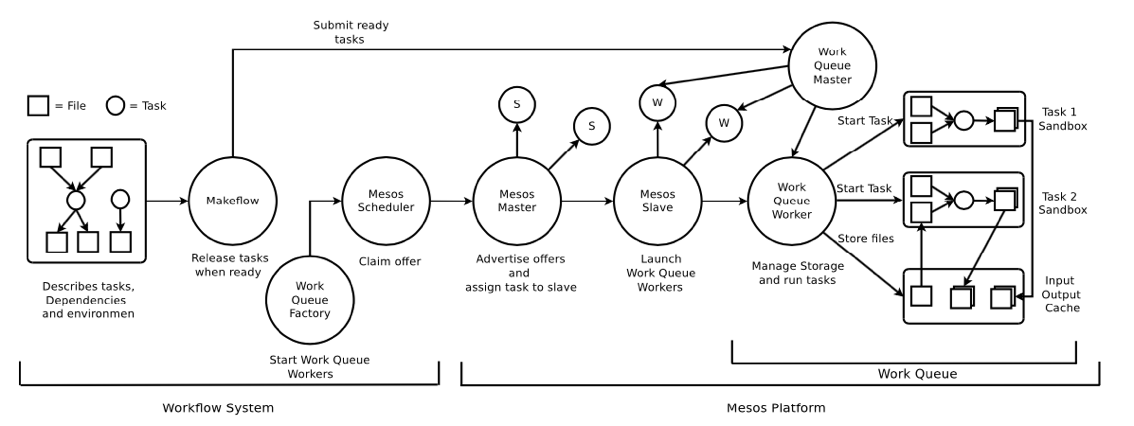
这两个方案的存在一个问题——
真实环境中,每个任务的资源需求大多都是未知的。如果有用户来定义每个任务的资源需求,肯能会出现需求过大,或者过小的情况。
· 在方案1、2基础上,启用Makeflow的Resource Monitoring:
测量运行时的资源使用情况并动态更新任务的资源需求。
除了每个Makeflow任务都将使用资源监视器线程运行之外,系统将照常工作。
实验和分析
实验
通常,工作流包括三种类型:
- 只包含长任务的工作流;
- 只包含短任务的工作流;
- 既包含长任务,也包含短任务的工作流;
本实验中选择使用 SHRiMP workflow。
该工作流包含三个阶段,第一阶段,执行一个长任务,第二阶段,并行执行多个短任务,第三阶段,整合所有分支的输出,生成最终的输出文件。
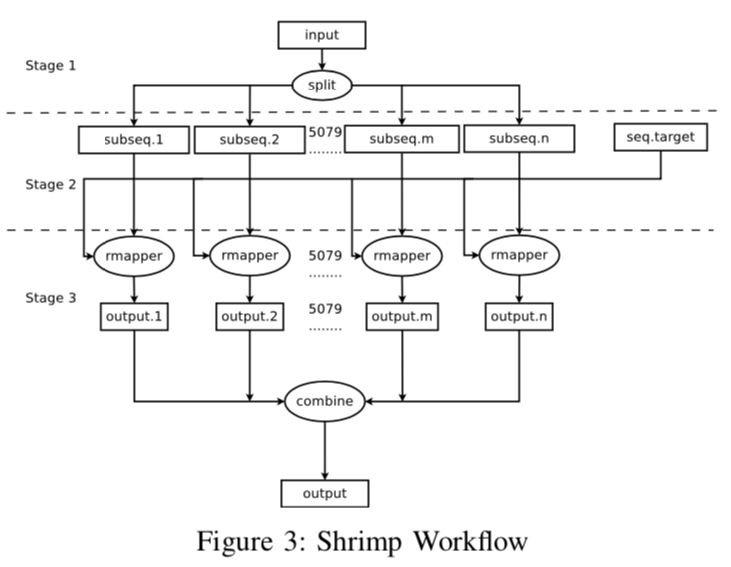
实验中,为了能够更直观地看到 Work QUeue 和 Resource Monitor 对 workflow 执行过程的影响,采用了4种部署方案:
- Makeflow + Mesos
- Makeflow + the resource monitor + Mesos
- Makeflow + Work Queue + Mesos
- Makeflow + Work Queue + the resource monitor + Mesos
分析
下图表格记录的是4种方案执行工作流的总用时、平均每个任务用时、平均数据传输率、平均CPU利用率。

从表格中可以看出,第一种方案的总执行时间最长CPU利用率最低。对比1、2方案和3、4方案,可以发现,启用 Resource Monitor 后,CPU利用率大大提升了。
还能看出,使用Work Queue 后,数据传输率也大大提升了。这是因为在不使用 Work Queue 的情况下,由于会不断重置 TCP 连接,所以时间开销变大。上一节的方案设计中就提到过,Work Queue 使用缓存目录来暂时存储输入输出文件,而且它只需要一个 TCP 连接就能传输所有任务的输入输出文件。这减少了执行器和 master 通过 HTTP 请求输入文件和传输输出文件的频率,降低 TCP 连接的开销。
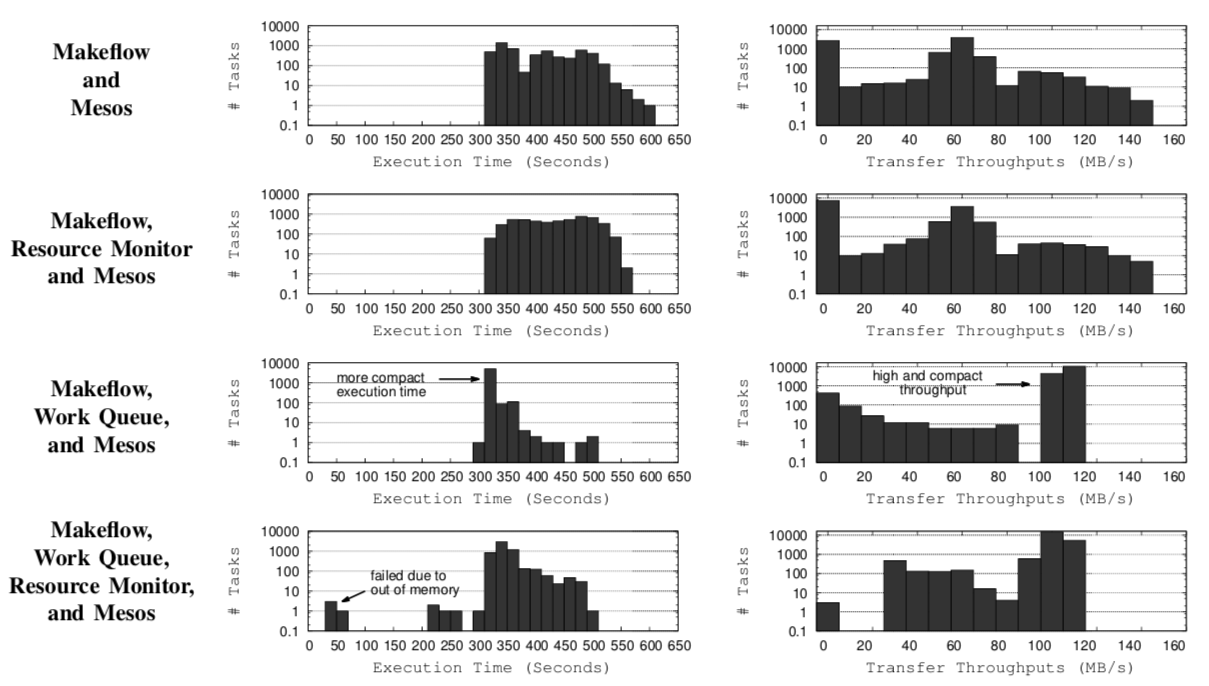
在该工作流的第二阶段,随着任务数量的增加,执行时间、数据传输速率的具体变化,通过下面的直方图展示。
在该工作流的整个生命周期中,随着时间的增加,CPU分配和使用的具体变化,通过下面的图展示。
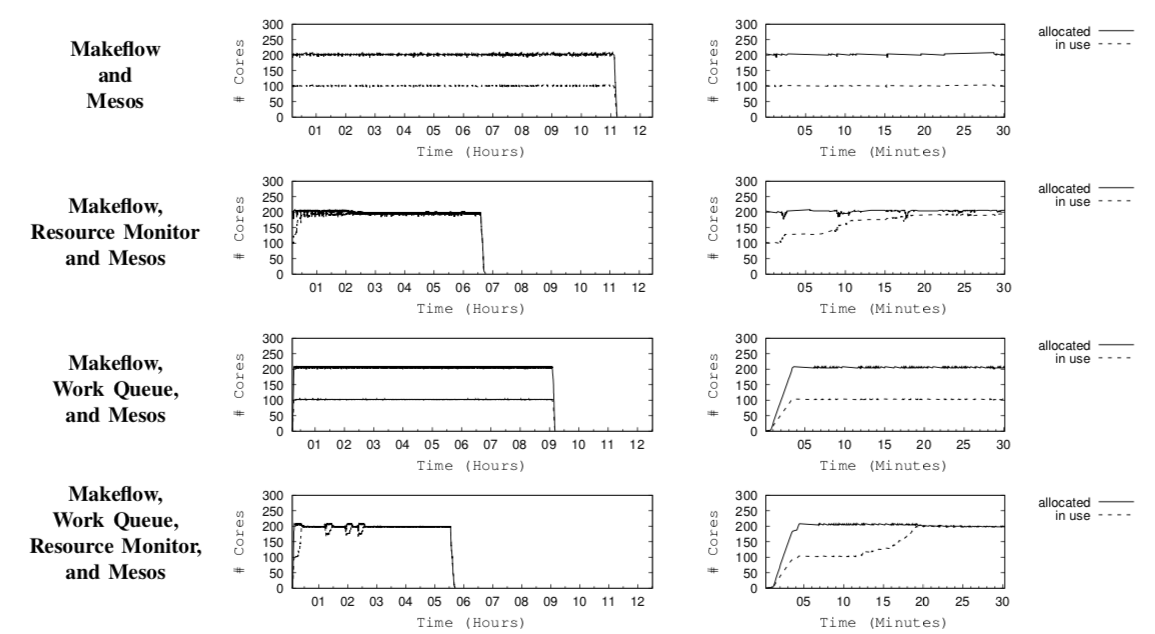
可以看出,启用 Resource Monitor 后,在最开始的30分钟内,CPU的使用会动态调整,利用率随之提高。
总结,在工作流系统和容器环境的结合中,数据传输的策略选择、每个任务资源需求的准确估计,两者对工作流执行的性能影响很大。
主要因为——传输大量小文件的非平凡开销(non-trivial expense)和 准确估计每个任务的资源需求很难。
相关工作
-
文中提到,现有的很多工作流系统(WMS)都有相似的 principle,所以本文提出的解决方案也可以用到这些 WMS 中。
-
Skyport:一个AWS/Shock的扩展,使用Docker容器技术自动部署一个独立的低开销的执行环境。
-
本文研究者之前的工作:将 Docker 融合到 Makeflow 和 Work Queue 中,在保证性能的前提下,让工作流中的每个 task 都有一个独立的执行环境。这里使用的容器管理平台是SGE。SGE使用「集中式粗粒度调度」模型,也就是单级调度。发现,这种情况下,工作流管理系统无法知晓整个集群的资源状态,而且会产生 HOL(Head-of-blocking)问题。基于这一点,本文采用了使用两级调度模型的Mesos,同样的系统还包括 YARN 和 HTCondor。
排头阻塞(HOL):
由于FIFO(先进先出)队列机制造成的,每个输入端的FIFO首先处理的是在队列中最靠前的数据,而这时队列后面的数据对应的出口缓存可能已经空闲,但因为得不到处理而只能等待,这样既浪费了带宽又降低了系统性能。
举个现实生活中的例子,这就如同你在只有一条行车路线的马路上右转,但你前面有直行车,虽然这时右行线已经空闲,但你也只能等待。
总结和感想
文中最后提出了两个未来工作的方向:
- 资源增强循环的间隔(Resource reinforcement loop)、运行任务的最大数量、总执行时间,三者之间存在联系,所以可以基于三者建立模型,更好地设置这三个参数。
什么是「Resource reinforcement loop」?
If new resource requirements do not suit the needs of tasks, the reinforcement loop will be activated again.
- Makeflow 和 Mesos 之间的带宽存在性能瓶颈,未来可以通过 Zookeeper 建立冗余服务,更好地扩展带宽,提高性能。
本文的研究模式很值得参考。文中也提过,在其他工作流系统中,提出的 4 中设计方案也是适用的。
此外,容器环境下的工作流执行合,研究点也有很多。如何连接工作流管理系统和容器管理平台?连接成功后,如何提高性能?调度策略该如何设计?等等,都值得思考。
另外,因为写博客的原因,再次回顾了这篇论文,发现了以前漏掉的点。在本文作者之前的研究中,也使用过其他容器管理平台,虽然没有现在比较火的Kubernetes,但是却提到了Kubernetes的前身Borg。文中提出,使用非两级调度模式的容器管理平台存在一些的缺点,所以在本文中使用了Mesos,这很值得思考。
* 下期预告 *
下周准备把上上次组会讲的论文搬上来。
《A hybrid evolutionary algorithm for task scheduling and data assignment of data-intensive scientific workflows on clouds》,这篇论文提出了新的 workflow 模型,并基于这个模型提出了一个新的调度算法。
-END-
附论文连接:《Deploying High Throughput Scientific Workflows on Container Schedulers with Makeflow and Mesos》
附组会PPT连接:PPT