这是一篇17年发在《Future Generation Computer Systems》上的期刊论文。文章提出了一个科学工作流的新调度模型,并基于这个模型提出了一个新的调度算法HEA (Hybrid Evolutionary Algorithm)。
新模型和旧模型相比,将 data 放到了和 task 同等重要的位置,同时考虑两者的调度方式。
现状和问题
过去,科学工作流的运行环境大多是在一个或几个高性能的服务器上,需要处理的数据量也不像现在这样庞大且增长迅速。即使是使用分布式集群,因为机器基本都在一个机房,或者相邻的机房,所以「数据传输」并不会成为工作流执行效率的瓶颈。
后来,随着「云计算」的出现,在云环境上运行工作流成为了一种新的趋势。云主机大多分布在不同的机房,甚至不同的城市,再加上庞大的数据量,「数据传输效率」开始成为影响「数据和计算密集型」科学工作流的执行效率的主要因素之一。
然而,很多关于 task scheduling 的研究,很少去考虑数据文件的调度问题。它们要么忽略这个问题,要么默认数据文件都已经分配到合适的机器上。
因此,本文提出了一种新的调度模型,并基于这个模型设计了一个新的调度算法。
主要贡献:
- 新的工作流模型:同时考虑task和data的分配;
- 用数学公式描述task调度和data分配问题;
- 基于新模型提出新算法,混合进化算法(HEA)
- 基于模拟环境和真实环境的实验评估;
PS:文中把定义的数学公式简称为 TaSDAP-IP(Task Scheduling and Data Assignment Problem as a mixed integer programming problem),算法简称为 HEA-TaSDAP。
新模型和调度算法
新模型
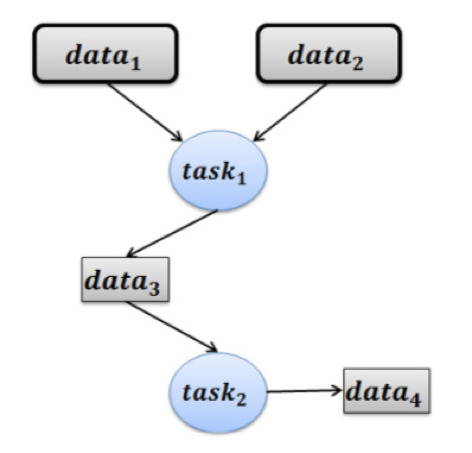
下图1是本文提出的新模型,图2是旧模型。在图1和图2中,每个圆圈代表一个task,可以明显地看出,新模型中还有代表data的标识,但旧模型就只有task。
新模型中,将data放到了和task同等的位置来考虑。
数学公式描述
符号标识

- static data —— 指工作流执行开始前需要的数据。
- dynamic data —— 指工作流执行中产生的「中间数据」。
- 左箭头为操作 read,右箭头为操作 write
- t_djp:虚拟机 j 对存储在虚拟机 p 上的数据 d 进行读/写操作的用时。
- x_idjpt:t时刻,任务 i(在虚拟机 j 上执行)是否开始 read 数据 d (存储在虚拟机 p 上)。
- x_djpt:t时刻,数据 d 是否开始从虚拟机 j 写入 虚拟机 p。
- y_djt:t时刻,数据 d 是否已经存储在虚拟机 j 上。
数学公式
15条约束公式,定义了 data 和 task 之间的依赖关系。
- 公式(1)最小化(整个工作流)执行时间;
- 公式(2)保证每个task都执行;
- 公式(3)和(4)保证每个写操作都完成;


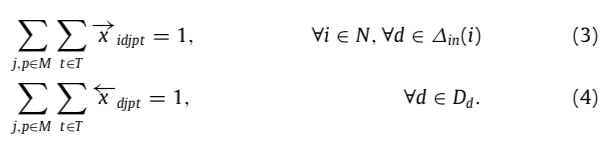
- 公式(5)和(6)保证 写操作的可行(VM j 对数据d的写只能当 VM j上的task 已经执行完毕了。task i 负责写数据d,那么数据d不能在 task i 执行前被写)。
- 公式(7)保证 task i 开始执行前,它需要的数据都读取完毕了(和15对比,读取操作完成)。
- 公式(8)表示一个VM 上,执行任务、写数据、读数据不能同时进行,每个时间段只可执行一个操作(?)。
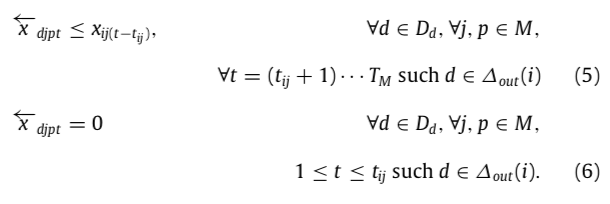
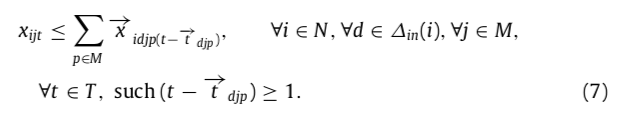
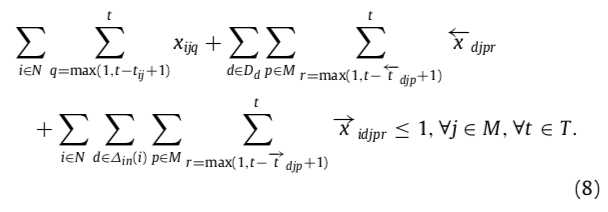
- 公式(9)保证开始前没有动态数据(临时生成的数据)。
- 公式(10)保证开始前,所有静态数据都已经就位。
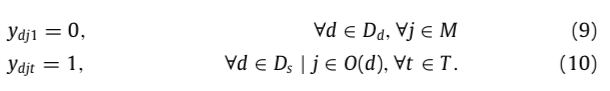
- 公式(11)和(12)保证连续的读写操作(11-写,12-读)。
- 公式(12):对于存在虚拟机 p 上的某个数据 d,同一时间只有一个 task 能进行读操作(?)。
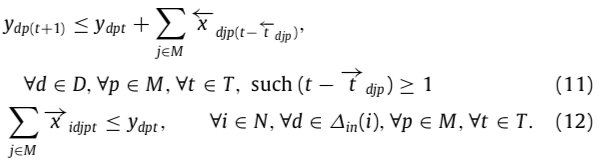
-
公式(13)存储约束(存储能力要满足data需求)
- 公式(14):每个 task 的执行完成时间必定小于等于最后的完成时间。
- 公式(15):进行读操作前,所有中间数据(Dd)已经生产并写好了(和7对比)。
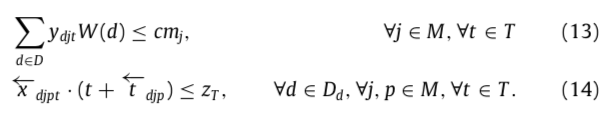
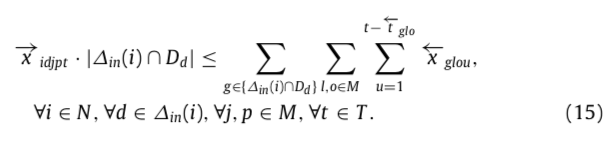
总结,15个约束公式,保证了:
- 写操作和读操作可行;
- 执行任务操作可行;
- 数据存储限制;
- 同一VM上,执行任务、写数据、读数据不能同时进行(见公式12)。
调度算法
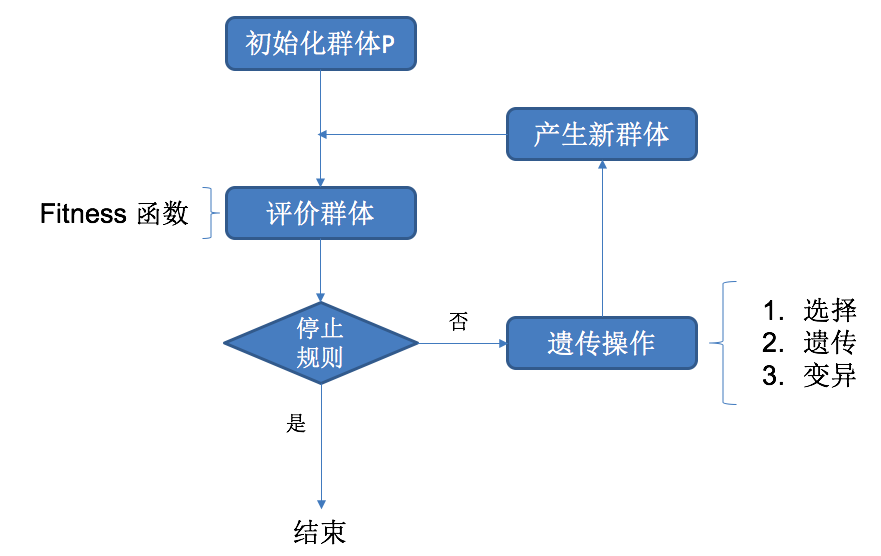
传统的遗传算法过程:
本文提出的混合遗传算法:
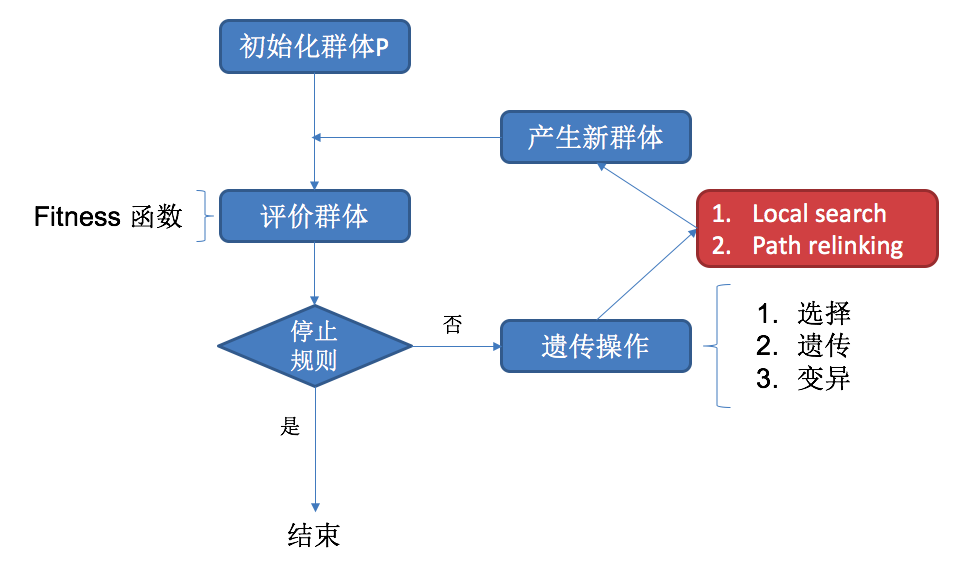
本文算法中,Fitness函数的评价指标是「工作流执行总时间最小」。
加入局部搜索(local search)和路径重连(path relinking)是为了尽量避免局部最优。
初始群体由多个个体(解决方式)组成,算法的目的就是尽可能找出「最优解」(理论上NP问题很难在有限时间内找出最优解,只能逼近)。
本文中的每一个体包含:
- 所有 task 和 data 都被分配到哪一个虚拟机上;
- task 的执行顺序;
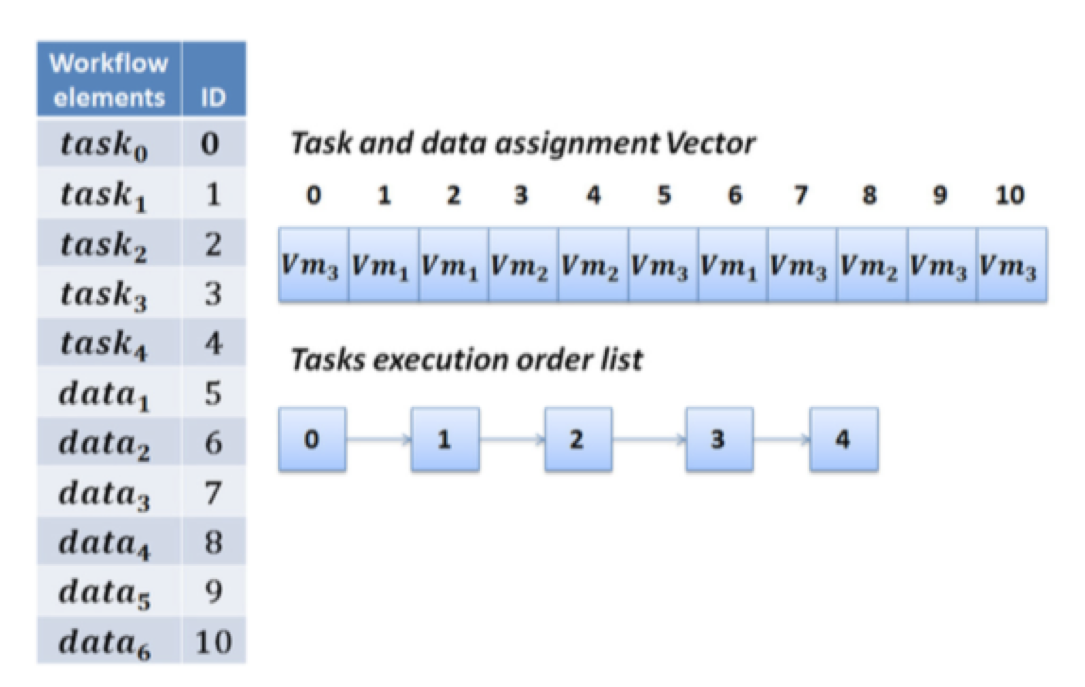
· 如何初始化群体?
80% 的结果由 MinMin-TSH 和 HEFT 算法产生。20% 的结果随机产生。
· 遗传操作
第一步,随机选择一定数量个体,从中挑fitness最好的作为父母
第二步,随机选择一个点,以改点为界限,分别选取父母的一部分,组合产生新的「孩子」。
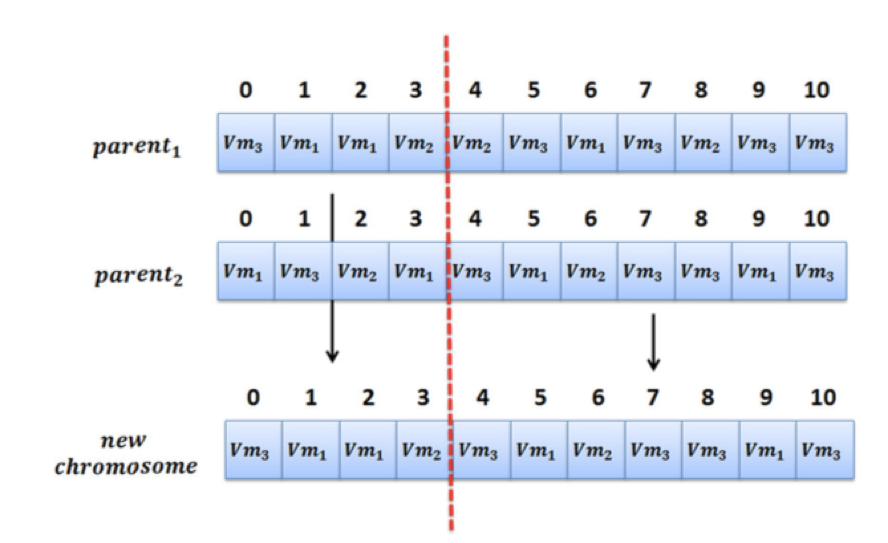
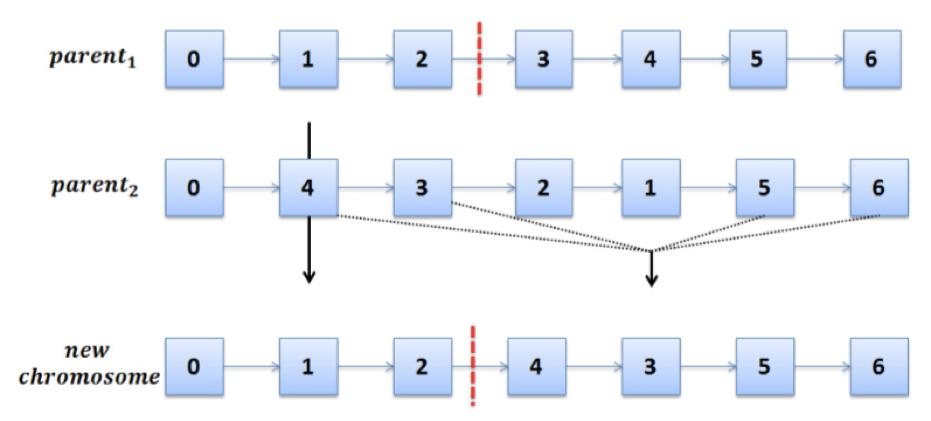
· 变异操作

变异只在「task和data的分配」上使用。因为实验表明变异操作对task执行顺序没有好效果,还增加了计算花费 。
- 约束条件:保证每个位置被修改概率为10%(10个位置);
- 之后会计算变异后 “个体”的权值(fitness),新取代旧;
· 局部搜索(Loacl Search)
第一步,交换两个元素(task/data)的值(VM);
第二步,交换任务执行序列的两个task的先后顺序;
第三步,改变task或者data的VM;
停止条件: 测试完所有可能的组合 or 效果有所提升(和当前最优相比)
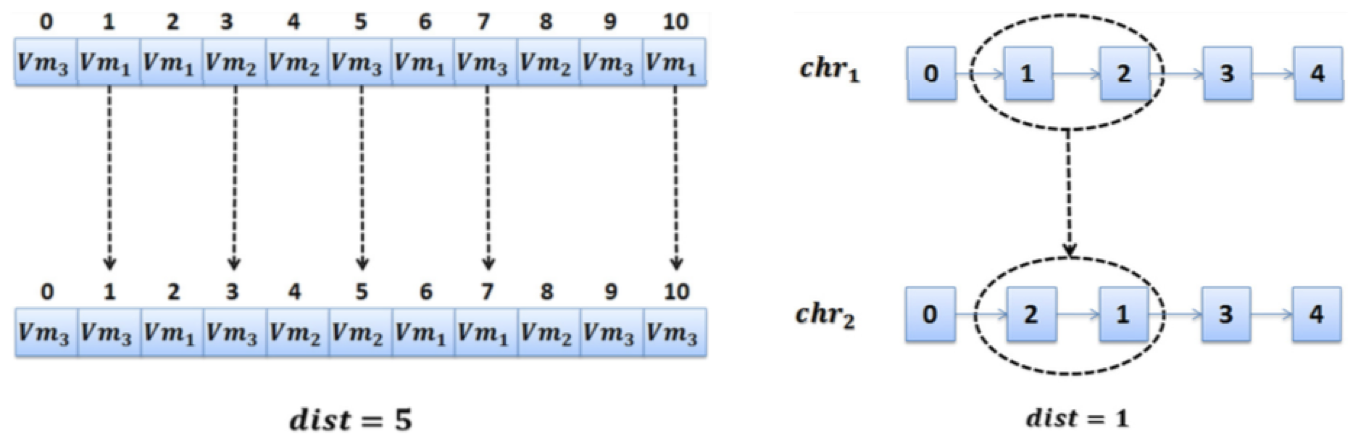
· 路劲重连(Path Relinking)
第一步,计算best和Elite_set中每个“个体”之间的距离;
第二步,生成中间解,更新best;
第三步,将当前最优解best加入Elite_set
- 路径重新链接是一种启发式方法,能够在其他两个路径之间生成中间解
- 限制:最多只有 群体P 的一半能加入“精英集合”(E set);α(本算法设定25%)为两个个体之间的距离(差异),控制精英集合的多样性;
实验和分析
实验
实验分为两个实验,模拟实验和真实实验。模拟实验的工作流来自 Workflow Generator。
模拟实验只和数学方式(使用CPLEX)对比。
CPLEX:将复杂的业务问题表现为数学规划 (Mathematic Programming) 模型,使用数学优化技术就资源的高效利用做出更佳决策。
真实实验和 HETF、MinMin-TSH 两个算法对比。
模拟实验中用到的工作流如下:

分析
下图是模拟实验的结果。
可以明显看出,本文提出的算法HEA-TaSDAP 比 使用数学方式得出解决方案要快很多很多。
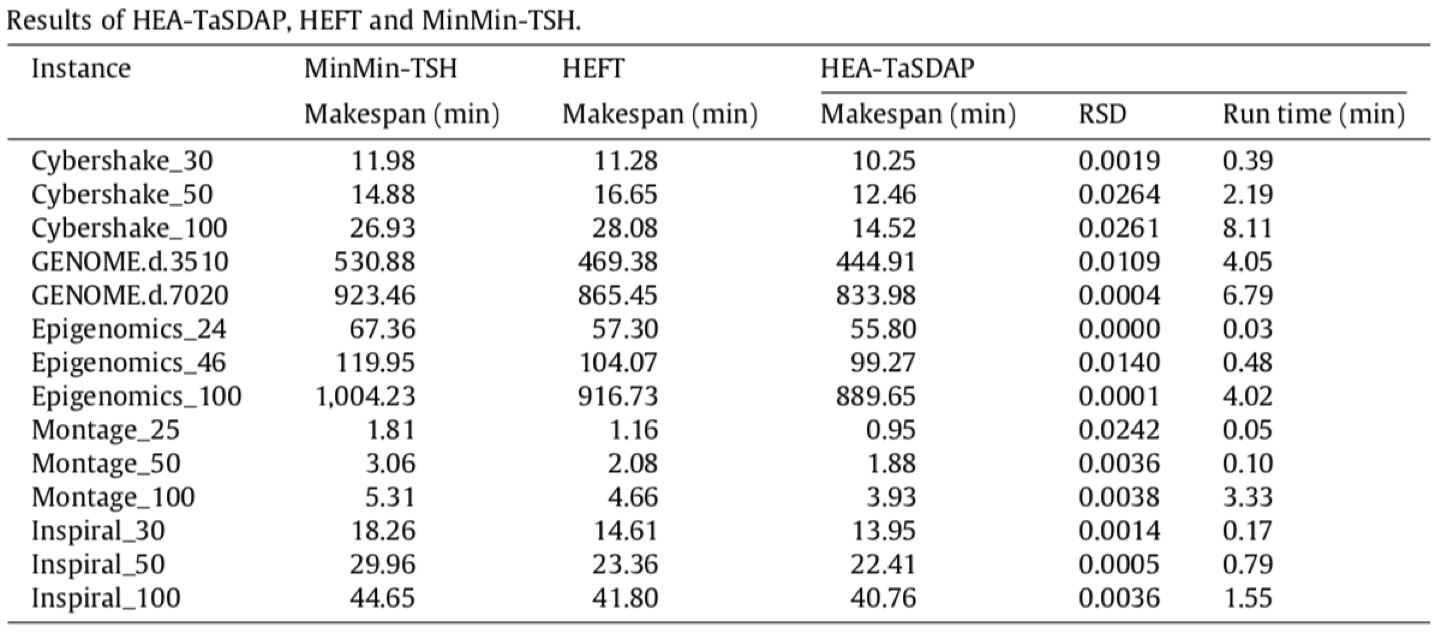
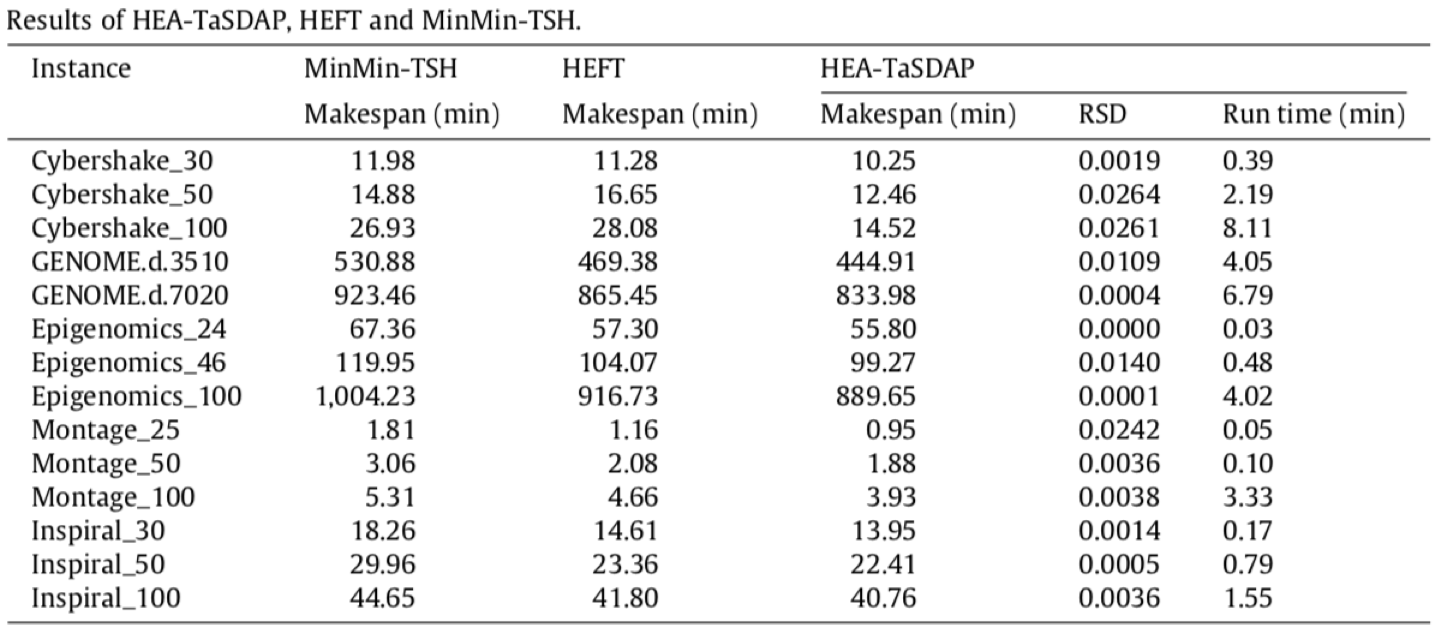
下两张图是真实实验的结果。
结合图1和图2,可以看出本文算法优于HEFT算法和MinMin-TSH算法,而且在数据传输效率上有着明显的提升。
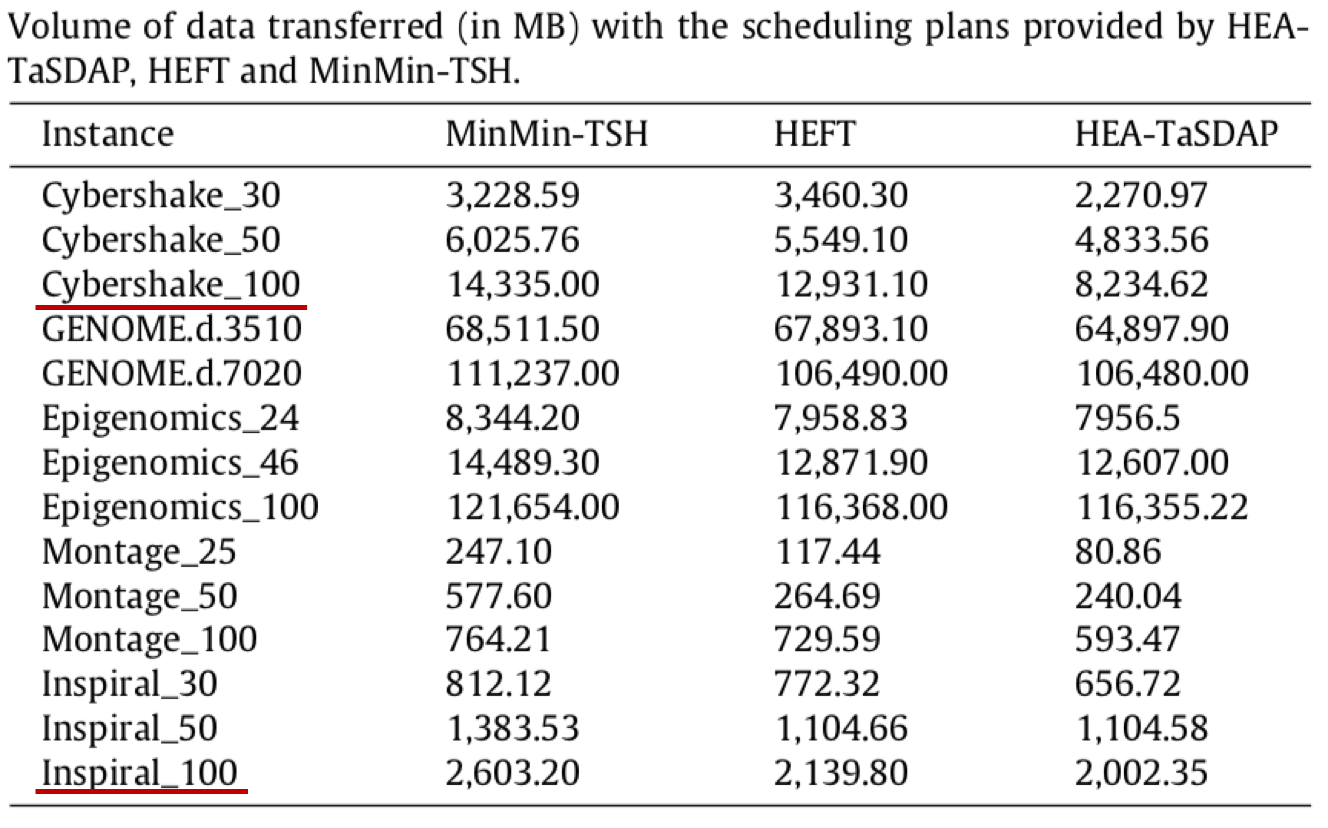
相关工作
- 很多工作流调度算法都是基于网格计算的,并不适用于云环境,不过它们也对云环境下的相关研究有所启发。—— 本文的「Related work」一栏介绍了很多相关paper。
- Juve等人的研究中,介绍来自不同科学领域的科学工作流,并总结了它们的特点。—— 对实验部分很有帮助
- MinMin-TSH 算法:一种被广泛使用的算法,基于贪心思想的启发式算法。本文用来做对比。
- 其他算法。本文介绍了很多,具体可看原文,就不一一列举了。
本文的「Related work」一栏相比其他paper挺长的,介绍了很多工作流调度方面的研究工作。个人觉得对了解这一领域的研究很有帮助。
总结和感想
重新回顾这篇paper后,关注点和第一次变得不一样了。之前,我的注意力都放在了如何基于本文提出的新模型,在容器化的工作流调度上做一点事,类似 「新模型+容器环境->新的工作流调度算法」这样。现在,反而觉得这几个部分更为重要——
- 提出的新模型(这一点还是不变);
- 实验部分(模拟实验+真实实验),特别是模拟实验部分用到的 Workflow Generator,还有IPerf;
- 相关工作部分,特别是的Juve的那篇介绍各个领域工作流及其特点的文章;
IPerf:一个TCP、UDP和SCTP的速度测试工具。在本文中用来测试数据传输速率。
第一次阅读的时候,相关工作部分都是粗略读过;这次回顾的时候,反而觉得这一块很有东西。
* 下期预告 *
下周打算看一看 Mesos 的论文。
才发现 Mesos 和 Borg 的论文断断续续看过一点,但都没有系统地看完。临时打算改变计划,这周看了一半的 《adCFS》先放一放,后两周把 Mesos 和 Borg 安排一下~
-END-
附组会PPT连接:PPT