Mesos是Apache下的开源分布式资源管理系统。它最初是由加州大学伯克利分校的AMPLab实验室开发的,后在Twitter得到广泛使用。这篇论文于2011年发布在NSDI会议上,里面详细介绍了Mesos的设计初衷、架构实现和实验评估。
现状和问题
文章中提到,当时的共享集群的两种常见解决方案都存在「资源利用率低、未实现高效数据共享」的问题。
两种常见解决方案是:静态分区集群,每个分区运行一个框架;为每个框架分配一组虚拟机。
大部分框架,例如Hadoop和Dryad都使用细粒度的资源共享模型。节点被细分为很多的“slot”,每个job有很多task组成,这些task被分配到不同的slot上。短任务,再加上每个节点上能够运行多个任务,使得Job之间可以实现高效的数据本地性(data locality)。Job能够快速地获得在存储了数据的节点上运行的机会。然而,由于这些框架都是独立开发的,所以无法跨框架执行细粒度的资源共享,这使得在它们之间高效地共享集群和数据变得困难。
因此,Mesos应运而生。
Mesos的设计目的:
- 多框架支持:设计一个能够支持现有框架和未来会出现框架的系统。挑战:由于每个框架的编程模型、通信模式、任务依赖和数据放置的不同,它们的调度需求也不同
- 可扩展性:调度系统必须扩展到数万个节点的集群。这些节点要运行数百个Job,每个作业可能包含数百万个task。
- 容错性和高可用性:由于集群中的所有应用程序都依赖于Mesos系统,因此系统必须具有容错性和高可用性。
调度上的挑战
- 复杂性。调度器需要提供一个足够明确的API来捕获所有框架的需求,并解决数百万任务的在线优化问题。即使这样的调度程序是可行的,这种复杂性也会对其可伸缩性和弹性产生负面影响。
- 新框架和新的调度策略会不断出现,所以不能保证可以满足所有的框架和调度策略。
- 许多现有的框架实现了它们自己的复杂调度,将此功能转移到全局调度程序将需要昂贵的重构。
综上,Mesos将调度权转交给各个框架,通过一个新的抽象实现,称为资源供给(resource offer)。它封装了框架可以在集群节点上分配以运行任务的一束资源。
Mesos根据组织策略(例如公平共享策略)决定给每个框架提供多少资源,而框架则决定接受哪些资源以及在哪些资源上运行任务。
虽然这种分散的调度模型可能并不总是能够产生全局最优的调度,但在实践中发现,它的表现非常出色,使得框架能够几乎完美地满足数据本地性(data locality)等目标。此外,resource offer 能够简单快速地实现,使Mesos具有高度的可扩展性和应对故障的鲁棒性。
目标环境与系统架构
目标环境
Facebook的Hadoop数据仓库。
Facebook将其Web服务中的日志加载到一个2000节点的Hadoop集群中,用于商业智能、垃圾邮件检测和广告优化等等应用。除了这些定期运行的“生产”Job外,集群还用于许多实验的Job,包括几个小时的机器学习计算,还有通过Hive的SQL接口进行交互提交的1-2分钟的即时查询。
大多数作业都很短(Job运行时间的中位数为84s),作业由细粒度的map和reduce任务组成(task运行时间的中位数为23s),如下图所示:
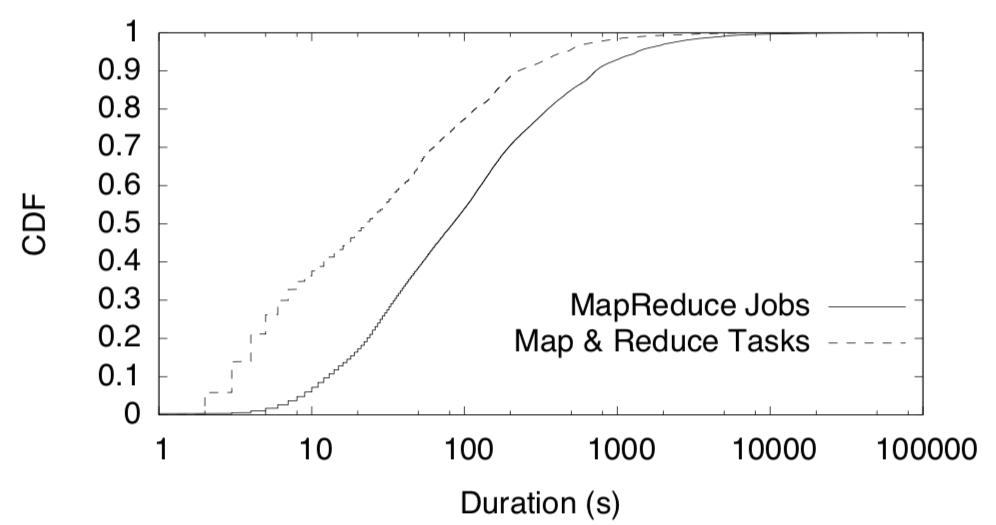
为了满足这些Job对性能的要求,Facebook使用了Hadoop的公平调度程序,该调度程序利用工作负载的细粒度特性来分配任务级别的资源并优化数据位置。
然而,这样集群就只能运行Hadoop作业。如果用户希望用MPI而不是MapReduce编写广告目标算法,那么用户必须单独为MPI部署一个集群并将数据导入其中。
为了解决这个实际问题,需要设计一个新的集群资源管理系统。
系统架构
设计理念
- 提供一个可弹性扩展的核心,使各种框架能够有效地共享集群资源。(新框架在不断产生,Mesos的核心架构也需要不断扩展)
- 定义一个接口,使跨框架的资源共享更加高效。除此之外,将任务调度和执行控制都交给框架自己完成。
- 在接口之上构建实现公共功能的高级库。这些库类似于外内核中的库操作系统。把各种功能(例如容错)放在库中而不是放在mesos中可以让mesos保持小而灵活的特点,并让库独立发展。
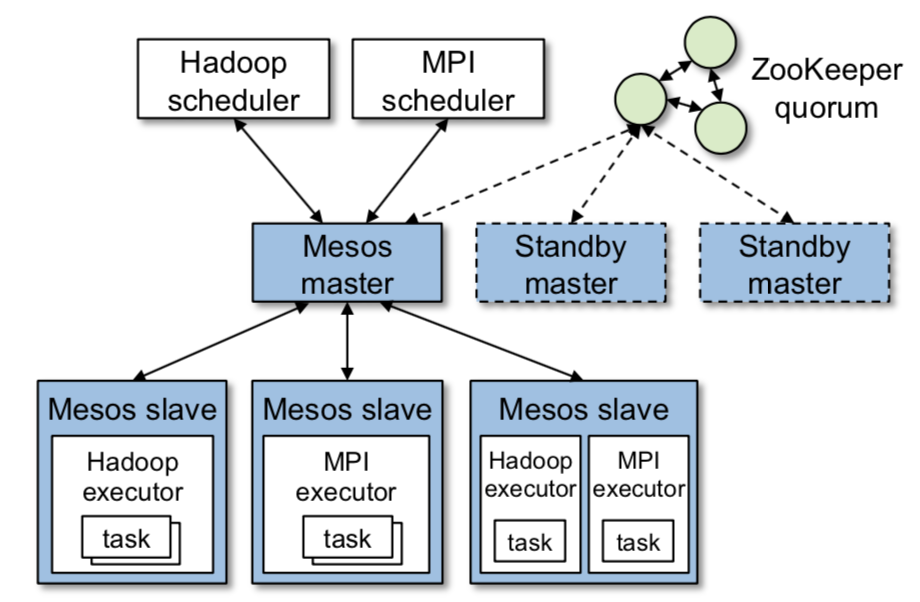
如上图所示,Mesos的组件主要包括master进程和slave进程,master管理所有的slave。slave后台进程运行在集群的每一个node上,框架将task运行在这些slave上。
master通过「resource offer」实现细粒度共享资源框架。每个「resource offer」就是一个空闲资源的list。master根据调度策略(公平策略或者优先级策略)决定给每个框架分配多少的资源。
每个运行在Mesos上的框架包含两个组件:
- 注册到master上的调度器(scheduler);
- 在slave节点上的执行器(executor);
当主框架决定每个框架要使用多少资源时,框架的调度程序选择要使用的资源。当一个框架接受所提供的资源时,它向Mesos传递一个它想要在其上启动的任务的描述。
拒绝机制:框架可以拒绝不满足约束条件的资源,等待能够满足条件的资源。Mesos不需要知道各个框架的资源约束条件。拒绝机制使框架能够支持任意复杂的资源约束,同时保证Mesos的简单性和可伸缩性。
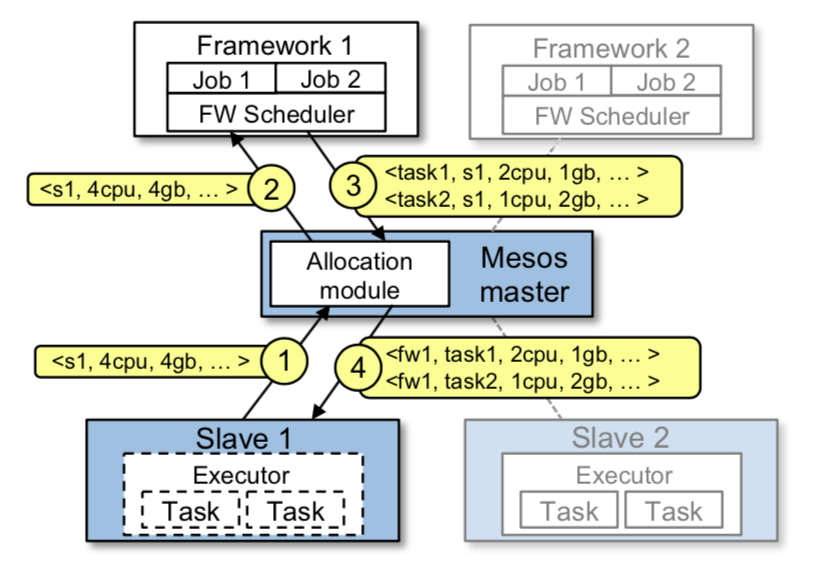
上图描述了一个Mesos调度的例子,具体步骤如下:
第一步,slave 1 向 master 报告它有4个CPU和4GB内存的空闲资源。然后,master 调用 allocation 模块,告诉它应该为 框架1 提供所有可用的资源。
第二步,master 将描述这些资源的「resource offer」发送给框架1。
第三步,框架的调度器向 master 报告将要在 slave 上运行的两个任务的信息,第一个任务需要 <2个CPU,第一个任务 <2 CPUs, 1 GB RAM>,第二个任务需要 <1 CPUs, 2 GB RAM>。
最后,master 将任务发送给 slave,slave 将合适的资源分配给框架的执行者(executor),后者依次启动这两个任务(用虚线框表示)。
因为还有1个CPU和1 GB内存的资源仍然是空闲的,所以分配模块现在可以将它们提供给框架2。
一、资源分配
Mesos将资源分配交给了一个可插拔的「分配模块」,可以根据需要定制「分配模块」。
目前已经实现的「分配模块」——
- 最大-最小公平策略;
- 优先级调度策略,Hadoop和Dryad使用了类似的策略;
考虑到这样的情况——集群的资源可能会被长任务占满,「分配模块」具有杀死(撤销)任何一个任务的权限。
「分配模块」杀死任务的策略包含两个机制——
-
允许框架保存一定资源量,避免任务丢失。虽然杀死一个任务对许多框架(如MapReduce)的影响很小,但这对具有相互依赖任务(如MPI)的框架是有极大影响的。(如果一个框架获取的资源低于其“需保证的分配”,则不应杀死它的任何任务;如果高于,则可能杀死它的任何任务)
-
Mesos需要知道哪些框架会获得更多的资源,从而确定何时触发「撤销任务」。各个框架通过调用API来告诉Mesos它们对资源的需求。
二、资源隔离
Mesos 利用现有的操作系统隔离机制,为运行在同一个slave机器上的各个框架的执行器提供性能隔离。
由于这些隔离机制对平台具有依赖性,Mesos通过可插拔的「隔离模块」支持多种隔离机制。
目前,我们使用OS容器技术隔离资源,类似Linux Containers和Solaris项目。这些技术可以限制进程树的CPU、内存、网络带宽和(在新的Linux内核中)I/O使用。这些隔离技术并不完美,但是与Hadoop这样的框架相比,使用容器已经是一个优势了,在Hadoop中,来自不同作业的任务只在不同的进程中运行。
三、可扩展性和鲁棒性
前提:任务调度在Mesos中是一个分布式的过程,所以需要它在应对故障问题上具有高效性和鲁棒性。
Mesos 通过三点实现——
-
过滤器。目前支持两种类型的过滤器:“仅提供列表L中的节点”和“仅提供至少有R资源可用的节点”。但是,也可以支持其他类型的过滤。(请注意,与一般约束语言不同,过滤器是布尔谓词,用于指定框架是否会拒绝一个节点上的一束资源,因此可以在主节点上快速计算这些资源。任何没通过框架过滤器的资源都会被框架全部拒绝)
-
将提供给框架的资源计入集群的分配中。由于一个框架可能需要时间来重新响应一个「resource offer」,Mesos 不可能一直等待框架的响应,所以先将这部分资源暂时记录到「已分配」中。这促使框架快速响应提供的资源,并过滤它们无法使用的资源。(该部分原文并未详细描述,仅为我自己的理解)
-
长时无响应则取消。如果一个框架在很长的时间内没有对一个offer作出响应,那么Mesos将取消这个「resource offer」,并将资源重新分给给其他的框架。
四、容错
- master故障。将 master 设为软状态(soft state)。使用ZooKeeper在热备份配置中运行多个master以进行领导人选举。
什么是soft state?介于stateless和stateful之间。master 会以 slave 的名义维护状态,但是仅仅维持一段时间,过了这段时间,master 就会将这些状态信息扔掉。(具体请参考这篇博客 -> 解惑soft state)
master设为soft state:这样一个新的master就可以从slaves和框架调度器所持有的信息中完全重建其内部状态。主服务器的唯一状态是active的slaves、active的框架和正在运行的任务的列表,这些信息足以计算每个框架使用的资源数量并运行分配策略。
使用ZooKeeper:当active状态的master发生故障时,slaves和schedulers将连接到下一个被选中的master,并重新填充其状态。
-
节点故障和执行器故障。Mesos向框架的调度器报告节点故障和执行器崩溃,然后,框架可以使用其选择的策略对这些故障做出反应。
-
调度器故障。Mesos允许一个框架注册多个调度器,这样当一个调度器发生故障时,另一个调度器会被Mesos的master接管。注意,框架必须使用自己的机制在调度器之间共享状态。
理论分析
一、定义, 标准和假设
3个标准,2个假设。
考虑3个标准:
- 框架的启动时间(ramp-up time):一个新框架完成资源分配的时间;
- 作业(Job)的完成时间:假设一个框架一个作业;
- 系统利用率:整个集群的(资源)利用率;
定义2个假设:
-
假设一个框架所要求的「强制性资源」的数量永远不会超过其保证份额。这样可以确保框架在等待「强制性资源」释放前不会发生死锁。
-
假设所有任务都具有相同的资源需求,并在名为插槽(slot)的机器片上运行,并且每个框架运行一个作业(Job)。
- 从两个维度来描述工作负载:弹性/刚性,任务持续时间分布。
一个弹性框架,比如Hadoop和Dryad,可以向上或者向下扩展其资源,也就是说,它可以在获取节点后立即开始使用它们,并在任务完成后立即释放它们。相反,刚性框架(如MPI)只能在获得固定数量的资源后才能开始运行其作业,并且不能动态地向上扩展以利用新资源或向下扩展,而不会对性能产生很大影响。对于任务持续时间,我们考虑了均匀分布和非均匀分布。
- 区分两种类型的资源:强制资源和首选资源。
如果框架必须获取某个资源才能运行,则资源是必需的。例如,如果框架无法在没有GPU的情况下运行,则GPU是强制资源。相反,如果某个资源不是必须的,只是获得这个资源后,框架能够运行得更好,那么它就是首选资源。例如,框架可能更“喜欢”在「存储其数据的节点」上运行,但如果有必要的话,也可以远程读取数据。
二、同构和异构
同构任务
考虑两种分布式任务:
- 所有任务的(时间)长度一样;
- 任务的(时间)呈指数增长;
对比两种框架:
- 弹性框架 —— 拿到资源就开始运行;
- 非弹性框架 —— 拿到所有资源才会开始运行,浪费了已经获得的资源;
如下表所示,对比了以上 4 种任务和框架结合,启动时间、作业完成时间和资源利用率的情况。
“T”表示平均执行时间。框架从没有插槽开始,“k”是框架在调度策略下有权获得的槽数,“βt”表示在框架一次获得所有k个槽时,一个作业完成所需的时间。

异构任务
- 包含长任务和短任务,长任务的时间比所有短任务的平均时间都要长。
最坏情况下,所有节点都被长任务占据,短任务需要等待很长时间才能被执行。
不过,当框架能够使用的slot越多,最坏情况发生的概率就会大大降低。
为了进一步减轻长任务的影响,可以扩展Mesos集群,并在每个节点上为短任务保留一定的资源。
除此之外,还可以将任务最大可持续时间与节点上的某些资源相关联。如果有任务的运行时间超过该设置,那么这个任务将被终止。这些时间限制可以暴露在提供给框架的「resource offer」中,允许他们自行选择是否要使用这些资源。
该方案类似于在HPC集群中为短作业设置单独队列的策略。
三、首选项(偏好)
- 前提:框架对不同插槽(slot)有偏好,并进行了首选项设置。
这会两种情况——
- 存在一种系统配置,其中每个框架获取其所有首选槽并实现其完全分配;
- 没有这种配置,即某些框架对首选槽的需求超过了可分配的。
第一种例子很简单,所有框架的需求都能满足。
第二种例子,无法满足所有框架的需求,所以就要用到公平调度策略。
但是,对Mesos来说有一个挑战——它不知道每一个框架的偏好,因此这里采用「彩票调度策略」
彩票调度:基本思想是向进程提供各种系统资源(如CPU时间)的彩票。一旦需要做出一项调度决策时,就随机抽出一张彩票,拥有该彩票的进程获得该资源。
四、框架的激励措施
- 讨论可以改进框架内Job响应时间的激励措施。
1. 短任务优先:
Mesos是适合短任务的资源管理系统
- 给短任务分配资源更方便;
- 当task丢失、出错、需要重启的时候,和长任务相比,短任务耗费的工作量更小;
2. 弹性扩展:
框架一旦获得资源,就可以开始“工作”,而不需要等到获取了所有的资源才开始“工作”。这使得框架能够更早地开始(和完成)其工作。此外,向上和向下扩展的能力还允许框架机会主义地抓住未使用的资源,因为它可以稍后就释放这些资源,而不会产生任何负面影响。
3. 不接受未知资源:不接受框架无法使用的资源。
这些激励措施能很好地提高资源利用率。
如果框架使用短任务,那么Mesos可以在它们之间快速地重新分配资源,从而减少新作业的延迟,以及减少撤销任务产生的工作量。
如果框架是弹性的,它们将机会主义地利用它们能获得的所有资源。
如果框架不接受未知资源,它们将把这些资源留给其他框架。
许多当前的集群计算框架都满足这些特性,例如MapReduce和Dryad,因为使用独立的短任务使负载均衡和故障恢复变得简单。
五、分布式调度的限制
1. 碎片化(Fragmentation)
|| 这部分在理解上有点问题,因此标蓝并附上论文原文。||
当任务具有异构资源需求时,分布式框架集合可能无法优化【bin packing】和集中调度程序。 (When tasks have heterogeneous resource demands, a distributed collection of frameworks may not be able to optimize bin packing as well as a centralized scheduler. )
但是,由于【不理想的 bin packing】而浪费的空间受到「最大任务大小和节点大小之间的比率」的限制。 (However, note that the wasted space due to suboptimal bin packing is bounded by the ratio be- tween the largest task size and the node size. )
因此,即使是使用分布式调度,在集群中运行“大”节点(例如多核节点)和这些节点中的“小”任务,也将获得较高的资源利用率。
另一个问题——
当资源被“短任务”占满后,“长任务”可能会长时间处于“饥饿”的状态。因为一个“短任务”完成后,释放的资源不满足“长任务”的需求,很快又会被其他“短任务”占用。
2. 互相依赖的框架约束
由于框架之间的密切依赖关系(例如,来自两个框架的某些任务不能被colocated),因此只存在一种集群的全局分配方式。
考虑到这种情况出现的概率太低,因此文章中没有过多讨论。
3. 框架复杂
使用「resource offer」 会让框架调度变得复杂。
然而,文中认为并不需要过多担心这一点。
首先,无论是使用Mesos还是集中式调度器,框架都需要知道它们(对资源)的“偏好”。在集中式调度中,框架需要告诉调度器它们对资源的“偏好”,而在Mesos中,框架必须使用这些“偏好”来决定接受哪一个资源。
第二,许多现有框架的调度策略都是在线算法,因为框架无法预测任务运行时间,所以必须能够处理故障和偏离(stragglers)。这些策略很容易通过「resource offer」实现。
实验分析
实验
分为两部分——
- 评估在四种不同工作负载中共享资源的效果;
- 通过几个小实验来评估开销、分散调度、专门框架(spark)、可扩展性和故障恢复;
四种框架包括:
- Hadoop实例,基于Facebook的工作负载,包含一系列小作业和大作业。(所有作业来自Hive benchmark,包含四种类型的查询);
- Hadoop实例,运行一组大批量作业(I/O敏感);
- Spark,运行一系列机器学习作业(CPU敏感);
- Torque,运行一系列MPI作业(SPEC MPI2007 benchmark,CPU敏感);
四种框架运行在两种环境中,实验通过对比这两种情况来评估Mesos ——
- 96个节点的Mesos集群;
- 24个节点的集群,将集群静态划分给四个框架;
分析
实验结果表明,和「静态划分」相比,Mesos能够实现集群资源的高利用率,而且作业的完成时间不是和「静态划分」差不多,就是高于「静态划分」。
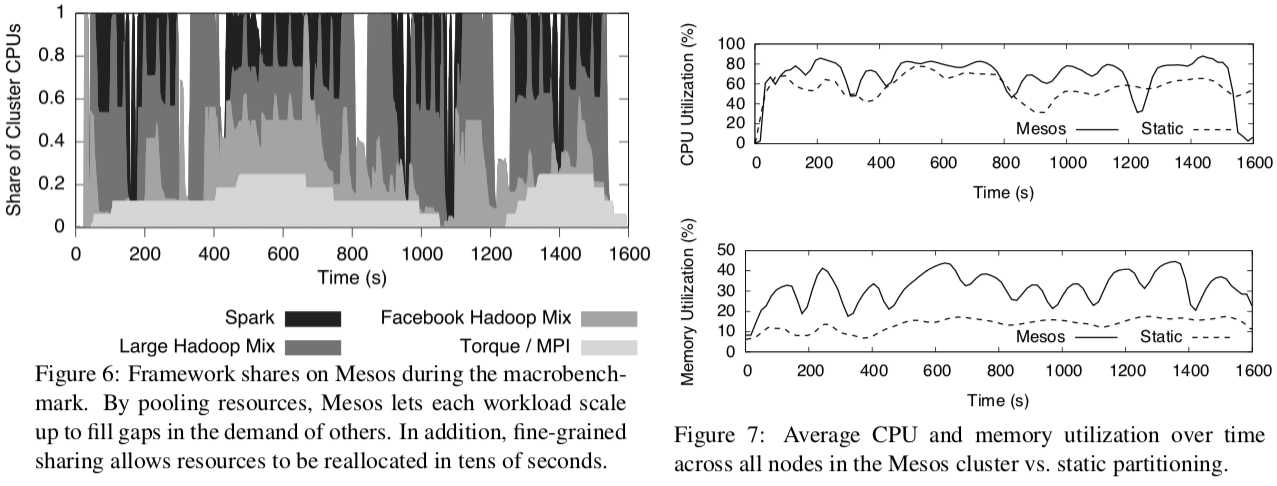
从上图的左边可以看到,当一些框架的资源需求较低的时候,Mesos允许其他的框架动态扩展,使得集群的资源大部分时候都处于忙碌的状态,提高了资源的利用率。
除此之外,细粒度的资源共享让资源能够在短时间内被重新分配(例如左图360s处,Facebook Hadoop开始运行作业)。
从右图可以清楚地看到,Mesos在CPU和内存的利用率上是高于「静态划分」的。
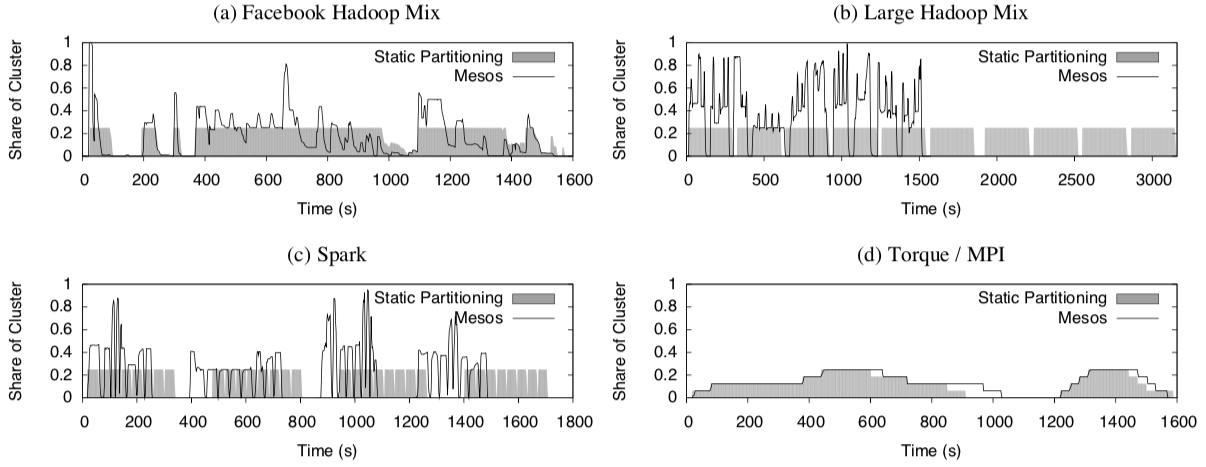
上图展示了 Mesos 和「静态划分」的资源分配随时间变化的情况。在Mesos中,不仅资源分配更灵活合理,而且作业会更快完成。
但是,Facebook Hadoop 和 Torque 在这一方面并没有明显的提升。从下面两张表可以更直观地看出来。
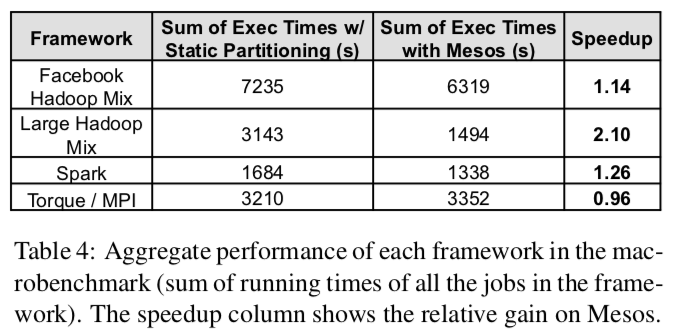
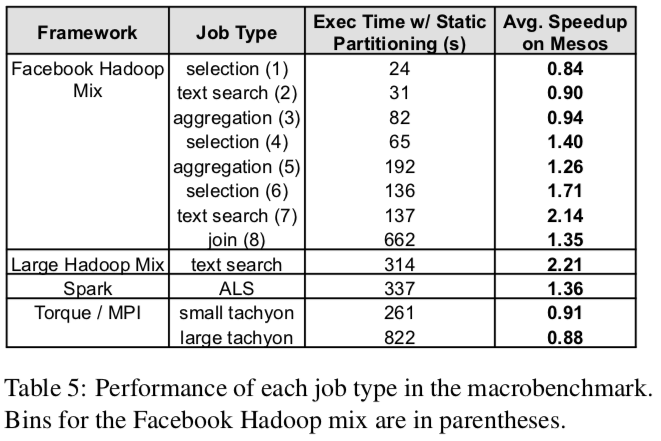
Facebook Hadoop 受限于“小作业”,这是因为Hadoop自身的公平共享策略和Mesos的公平共享策略互相影响导致的。
Torque 运行的是MPI作业,前文有提到过 MPI 是刚性框架,Mesos在弹性伸缩上的优势并不能很好地体现。再加上 Torque 给每个节点都分配等量的工作,于是它的运行速度就和最慢的节点一样。
- 开销评估:
在50节点的集群上单独运行一个框架,对比使用Mesos和不使用Mesos的开销。
- MPI:运行 High-Performance LINPACK 作为benchmark;
- Hadoop:运行 WordCount 作业作为benchmark;
结果表明,Mesos上的开销会少 4%。
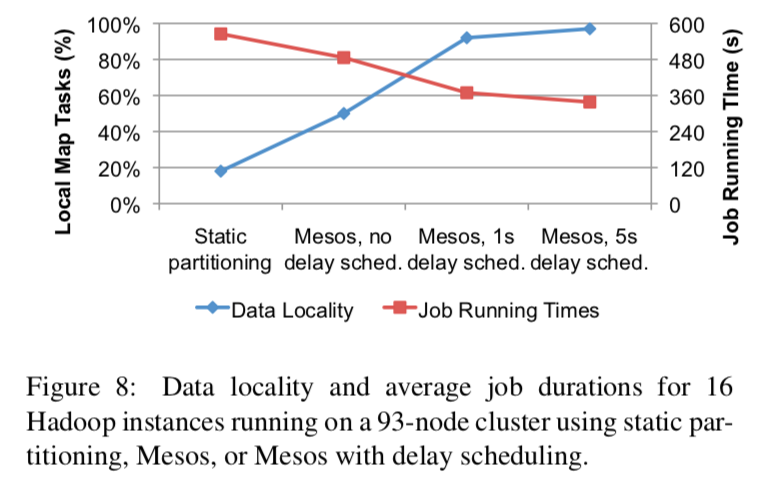
- 延迟调度(分散调度):
评估 Mesos 的「Resource offer」机制如何控制 「任务的位置」和「数据的位置」。
从下图可以看出,即使不使用延迟调度,Mesos实现「数据本地性(data locality)」的概率也比「静态划分」要高。
- 专用框架(Spark):
评估基于 Mesos 开发出来的 Spark 专用框架在运行迭代任务时,和Hadoop对比,效果如何?
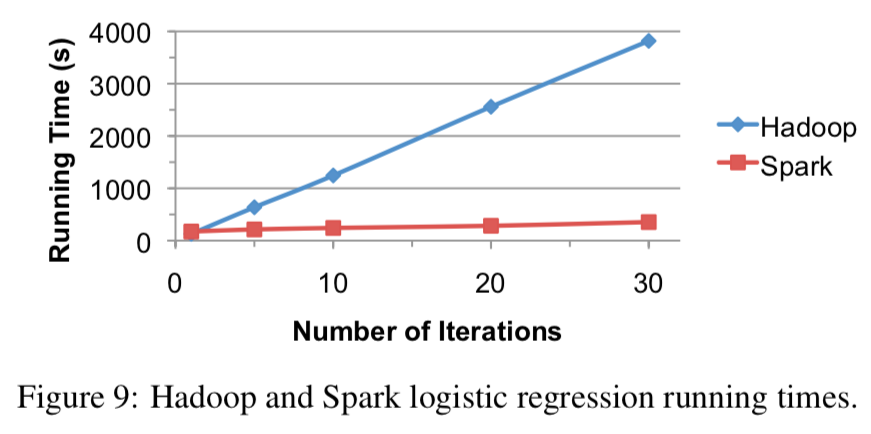
- 可扩展性:
为了评估 Mesos 的可扩展性,模拟了在99个Amazon EC2服务器 节点上运行50,000个 slave 代理的实验环境。
在实验环境中运行200个框架,当集群达到稳定状态(即200个框架实现了公平共享策略并分配了所有资源),就启动一个测试框架。该测试框架运行一个10秒的任务,然后测量这个框架需要多长时间才能完成任务。
结果如下图,即使在50,000个节点上,开销依然很小(小于1秒):
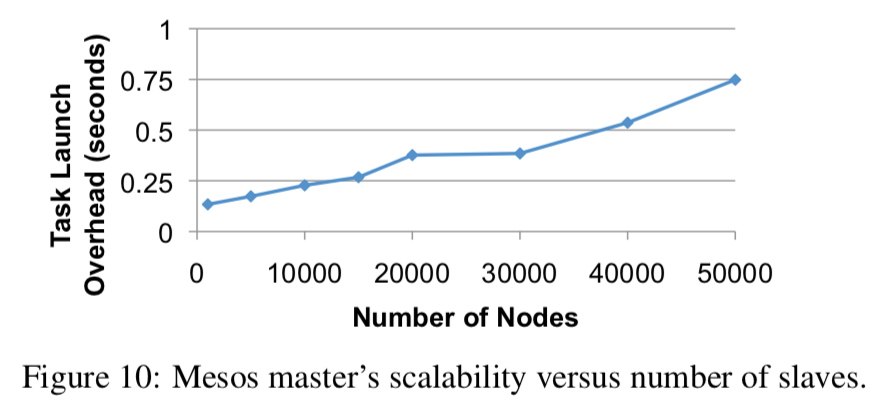
另外,文中提到,由于EC2虚拟环境限制了超过50,000个 slave 服务器的可扩展性,所以实验最多只能测试到50,000个 slave,这是EC2自身的限制。
- 容错性(故障恢复):
实验环境:62个节点,200~4000个salve代理程序,其上运行200个框架。
MTTR表示所有slave和框架连接到新master上的时间。在所有的测试案例中,MTTR都在4到8秒之间。
- 性能隔离
在前文的系统架构-资源隔离那一块(对应论文3.4部分)已经进行了说明。
论文中表示,读者具体可通过阅读这篇论文来更全面地评估操作系统隔离机制 -> 《Quantifying the performance isolation properties of virtualization systems》
相关工作
1. HPC和Grid:
高性能计算(HPC)
HPC的目标环境通常由专门的硬件组成,例如Infiniband和SAN。在这些硬件中,作业不需要调度到数据所在的位置。此外,每个作业都是紧密耦合的,通常使用“屏障(barriers)”或消息传递。因此,每个作业都是单一的(monolithic),而不是由细粒度的任务组成,并且在其生命周期中不会改变其资源需求。
HPC调度程序使用集中调度,并要求用户在提交作业时声明所需的资源,然后,对作业进行粗粒度的资源分配。与Mesos不同,它不允许作业本地访问分布在集群中的数据。此外,作业不能动态增长和收缩。相比之下,Mesos支持任务级别的细粒度共享,并允许框架控制它们的位置。
网格计算(Grid)
网格计算重点关注这样的问题——使不同的“虚拟组织(virtual organization)”能够以安全和互操作的方式,共享那些分布在不同地方且单独进行管理的资源。
Mesos可以很好地应用于那些位于「larger grid」的“虚拟组织”中。
2. 公有云和私有云:
它们在设计上和Mesos有相同的目的,例如:通过提供低层级的抽象(vms)来隔离应用程序。
不过,在几个重要方面,它们和Mesos并不一样。
首先,相对粗粒度的VM分配模型导致资源利用率和数据共享效率低于Mesos。
其次,这些系统通常不允许应用程序指定超出所需虚拟机大小的配置需求。相比之下,Mesos允许框架有更多的选择(允许超额分配?)。
3. Quincy:
Quincy是一个公平的Dryad调度程序,它对Dryad基于DAG的编程模型使用集中调度算法。相反,Mesos提供了更低层级(lower-level)的资源抽象,以支持多个集群计算框架。
4. Condor:
使用一个特定的语言(ClassAds)来将 Job 和 node 进行 match。显然,对于框架来说,这在resource offer上是不够灵活的,而且对于有自己调度器的框架,和Condor结合是很困难的。
5. 下一代Hadoop:
文中提到,当时雅虎宣布准备对Hadoop进行重新设计,计划使用两级调度模型,每个应用程序主程序都从中央管理器请求资源。
感觉这应该就是 Hadoop1.0 到 Hadoop2.0 的改变,Yarn这个资源管理系统的出现?
总结和感想
这篇论文看的比较久,有些地方看的不是很懂(包括博客里标蓝的部分),所以写的比之前几篇都详细,方便未来回顾。
看完后有几个问题,在这里记录下——
- 系统架构-资源隔离部分提到的:Linux container等内核虚拟化技术和进程隔离之间的对比?
- 文末提到的Hadoop的新版本,Hadoop 1.0 和Hadoop2.0 的对比?基于Hadoop2.0诞生的yarn,它和Mesos的对比?
- Spark官网提到从2.0开始就弃用了Mesos的“细粒度模式”,这是为什么?具体参考Spark官网提出的理由和讨论,后续阅读并理解下吧。
- “细粒度”和“粗粒度”之间的对比(虽然之前组会上也介绍过来,但感觉理解的还不够深入)?「动态分配+粗粒度」又是怎么回事(在Spark讨论弃用“细粒度”模式中看到的)?
* 下期预告 *
之后的安排:
- 阅读Borg和Yarn的论文,然后尝试写一下三个系统的对比。
- 尝试解决上面提到的4个问题。如果可以,也写成博客的形式。
-END-
附论文连接:《Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center》