Spark on Mesos两种模式的学习,解决阅读Mesos论文后遇到的问题。
这篇是后续阅读01,前文请见这里。
问题:
Spark官网提到从2.0开始就弃用了Mesos的“细粒度模式”,这是为什么?“细粒度”和“粗粒度”之间的对比?Spark on Mesos中的「动态分配+粗粒度」又是怎么回事?
一、粗粒度和细粒度
粒度(Granularity):粒度是指系统被分解成小部分的程度,它是一个更大的实体被细分的程度。例如一栋大楼可以认为是由好几个楼层组成(粗粒度),也可以认为是由无数房间组成(细粒度)。
——维基百科
粒度似乎是根据项目模块划分的细致程度区分的,一个项目模块(或子模块)分得越多,每个模块(或子模块)越小,负责的工作越细,就说粒度越细,否则为粗粒度。
——引用自这篇博客
粗粒度(Coarse-grained):和细粒度相比,粗粒度是更大的组件。简单来说,它可以由一个或多个细粒度的组件(服务)组成。
细粒度(Fine-grained): 较小的组件,可以由它组成更大的组件。
这里需要提一下,粗粒度并不总是意味着更大的组件。上面的对比描述只是为了更方便理解。
如果按“粗(Coarse)”的字面意思,它意味着苛刻,或者不合适。例如,在软件项目管理中,如果将一个小型系统分解为几个组件,这些组件大小相等,但复杂性和功能不同,则可能导致粗粒度。相反,对于细粒度划分,将根据每个组件所提供的功能的内聚性来划分组件。
——引用自Stack Overflow的回答
在Mesos中:
不同情况下,粗粒度和细粒度的概念是不一样的。这里通过两个例子来简单描述下Mesos中的“粗粒度”和“细粒度”是怎么一回事。
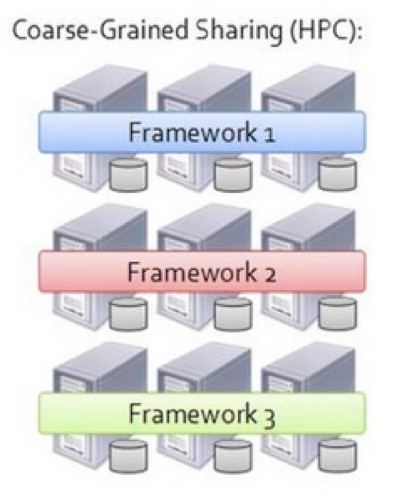
1. Mesos和HPC对比:
- HPC(高性能计算)
HPC的资源共享是粗粒度的。在HPC的应用环境中,“作业”不是由更细粒度的“task”组成,并且在生命周期中不会改变对资源的需求。
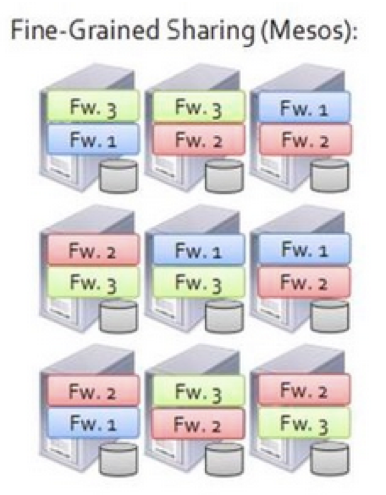
- Mesos
在Mesos中,节点被细分为“slot”,“作业”被细分为“task”,这些“task”可以运行在不同的“slot”上。“task”完成后,被占用的资源能够短时间内被重新分配给其他“task”。
2. 以Spark on Mesos为例:
- 粗粒度模式:
静态配置资源。每个应用将以FIFO策略独占资源(通过设置可修改应用最大能占用的资源,例如最大可使用的cpu核数、内存。默认是独占全部资源)。
粗粒度模式的好处是启动开销要低很多,但坏处是在应用程序的完整持续时间内将一直保留占用的集群 资源。
- 细粒度模式(已弃用):
在“细粒度”模式下,每个Spark执行器中的Spark任务都作为独立的Mesos任务在集群中运行。它允许多个Spark(或者其他框架)的实例以细粒度的方式共享内核。这样随着应用的扩展和收缩,它能够动态地获得更多或者更少的内核数。当某个实例不执行时,它所占用的CPU资源将别被其他实例使用,提升了CPU使用率。
这种模式下,启动每个任务时都会增加额外的开销,所以此模式不适用于有低延迟要求的环境,如交互式查询或Web服务请求。
需要注意的是:虽然在细粒度模式下,当Spark任务终止时,它将释放占用的内核资源,但它不会释放占用的内存资源。因为JVM不会将内存返回给OS,哪怕是Spark执行器处于空闲状态,也不会。
二、Spark 为何弃用“细粒度”模式?
官方放出了关于弃用的理由:
- 代码/维护太复杂: 两种模式在很多功能、代码上是重复的,这会导致细微的差别和错误。
- 它并没有被广泛地使用: 在调查使用“细粒度”模式的过程中,回复者很少。详细讨论见这里。
- 类似的功能可以通过「动态分配+粗粒度模式」来实现。
具体的讨论见这里。
总结下在上面的讨论中提出的两个问题:
- Mesos不支持每个slave节点有多个executor(这里是指一个框架在一个slave 上只能有一个executor)。这个问题似乎已经通过外部补丁解决了(具体见这里)。
- 其中一个讨论者表示他在使用ganglia监控spark集群时,CPU的利用率趋于平稳,没有看到切换为「动态分配+粗粒度模式」的优势。(这个问题直到讨论结尾也未得出结果)
三、动态分配+粗粒度模式
Spark 提供了一种机制,可根据工作负载动态调整应用程序占用的资源。这意味着,“粗粒度”模式下,如果应用程序不再使用资源,它将不会一直占用这些资源,而是把它们还给群集,并在有需求时再请求这些资源。
此功能默认是禁用的,可在所有粗粒度群集管理器(即standalone模式、YARN 模式和Mesos粗粒度模式)上使用。
Mesos只支持“粗粒度”模式的动态资源分配。当「动态分配」被启用,Mesos就可以重置应用程序的执行器。
这个功能通过Mesos Shuffle Service实现,需要在每个slave节点上运行:
1
$SPARK_HOME/sbin/start-mesos-shuffle-service.sh
并且将下面的参数设置为“true”:
1
spark.shuffle.service.enabled
Mesos supports dynamic allocation only with coarse-grained mode, which can resize the number of executors based on statistics of the application.
The External Shuffle Service to use is the Mesos Shuffle Service. It provides shuffle data cleanup functionality on top of the Shuffle Service since Mesos doesn’t yet support notifying another framework’s termination.
——引用自Spark官方文档
总结和后记
在《Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center》论文中,细粒度资源共享是它的重要特点和优势,但是在后续阅读中发现,细粒度模式在很多应用环境中可能并不适用(例如Spark。其他的框架应用暂不清楚)。
另外,发现之前的论文阅读笔记《Deploying High Throughput Scientific Workflows on Container Schedulers with Makeflow and Mesos》中对Mesos二级调度的解读和配图有问题,顺便做了修改。
-END-