本文介绍了一种使用图神经网络进行多指标异常检测的新方法。在预处理阶段,使用了计算协方差的方式。在模型训练阶段,结合了 AutoEncode 和 Conv-LSTM。
在实验部分,不仅使用人造数据,还使用真实的发电厂运维数据进行对比。对比的方法包括OC-SVM、DAGMM、ARMA、LSTM-ED等多个经典算法。
背景
在现实环境中存在的大部分系统都很复杂复杂,监视这些系统会获取大量的多维数据,而基于现实环境复杂系统的异常检测就是要根据这些数据检测出异常并对异常进行判断。系统能自行修复的“小异常”不需要上报,而无法自行修复的“严重异常”就要及时上报。
除此之外,大量的监测数据都是无标签的,而打标签又会非常浪费人力or时间资源,所以选择有监督算法在这种情况下往往是不太可行的。相比之下,无监督算法会更适合现实情况,但现有的无监督算法也存在以下问题,导致异常检测不够准确:
- 多元时间序列数据存在时间依赖性,而部分算法(距离/聚类算法,如KNN,One-Class SVM等)无法跨不同时间步捕获时间依赖性;
- 现实中,多变量时间序列数据通常包含噪声。当噪声变得相对严重时,它可能会影响速度预测模型的泛化能力(例如ARMA、LSTM-ED)
- 现实中,需要对异常进行评级。现有的根本原因分析方法对噪音敏感,无法处理此问题(如因果异常排序(RCA))。
为了研究方便,假设异常的严重程度与异常的持续时间成正比,也就是越严重的异常持续时间也越长。具体可看下图,A2异常比A1异常持续时间长,因此判定A2异常程度更严重。
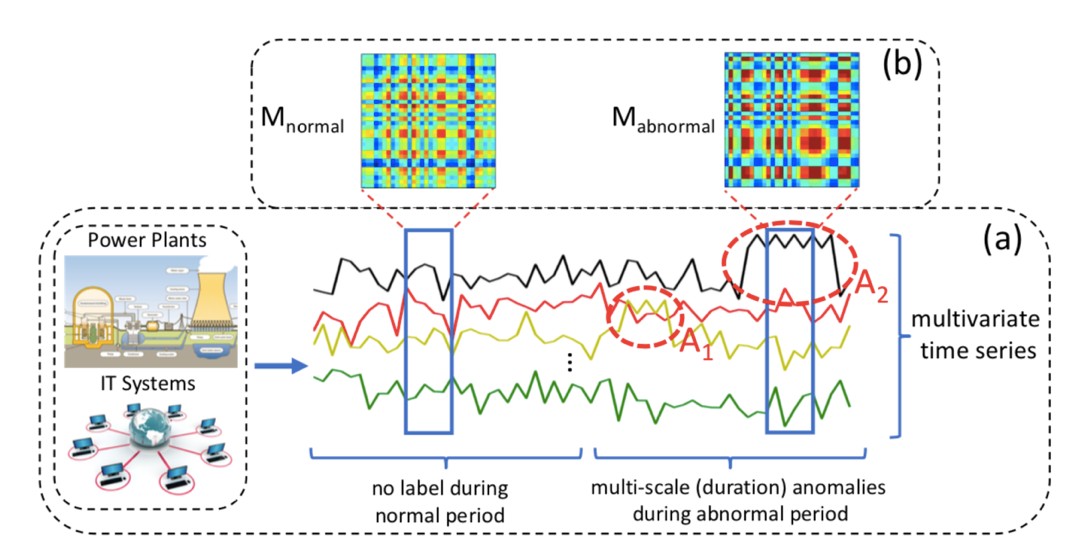
综上,本文提出来一种名为MSCRED的算法(多尺度卷积递归编码器解码器 )。
相关工作
传统的异常检测方法:
- 距离方法(如KNN)
- 聚类方法
- 分诶方法(如One-Class SVM)
以上方法在多变量时间序列上可能无法很好地工作,因为它们无法有效地捕获时间依赖关系。为了解决这一问题,时间预测方法,如自回归滑动平均(ARMA)及其变体,被用于建模时间依赖性和异常检测。但是,这些模型对噪声敏感,因此在噪声严重的情况下,异常检测准确率会下降。
基于深度学习的无监督异常检测算法:
- 深度自编码高斯混合模型(DAGMM):综合考虑了深度自编码和高斯混合模型对多维数据密度分布的建模。
- LSTM编解码器:利用LSTM网络对时间序列的时间依赖性进行建模,比传统方法具有更好的泛化能力。
尽管这些方法很有效,但它们不能同时考虑时间相关性、抗噪声性和异常严重程度。
算法模型
1.面对的挑战
- 由于无法提取时间关系,如果将适用于非时序数据的算法直接用于时序数据,可能会失效。
- 实际情况下的监测数往往都包含噪声,这会影响算法的精准度;
- 实际场景对细粒度的诊断结果有高要求,包括根因分析和异常严重程度的判断;
2.主要贡献
- 同时考虑异常检测、根本原因识别和异常严重性(持续时间)三方面,不同于过去那些独立探讨单个问题的研究;
- 引入系统特征矩阵的概念。通过卷积编码器对传感器间相关性进行编码,将事件模型与Conv-LSM网络结合,并通过卷积解码器重构特征矩阵。
- 首个考虑多变量时间序列相关性的异常检测模型。
- 使用真实的发电厂数据进行对比实验,结果显示MSCRED的性能优于最新的基准方法。
预处理
计算多元时间序列两两之间的协方差,将多元时间序列数据转换为多分辨率特征矩阵,再将特征矩阵作为 AutoEncoder 的输入。
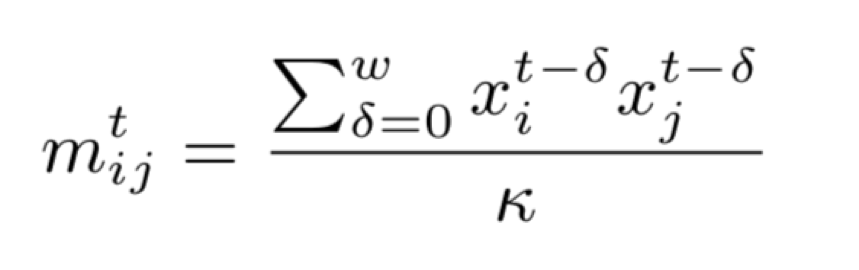
计算公式如上图,对于长度为 T,包含 n 个特征的时间序列数据,在每一个时间点 t (t < T), 取长度为 ω 的数据段,对 n 个特征两两计算内积,得到大小为 n*n 的特征矩阵。
优点:
- 如果不同特征上的噪声是彼此无关的,相关计算可以消除这些噪声的影响;
- 可以通过观察特征图上各个位置的重建误差分布便捷地对产生异常的特征进行定位;
- 可以通过比较不同时间尺度特征矩阵的重建误差推断误差的严重程度。
缺点:
- 增大了输入数据的规模,从而增加了模型的计算量。
模型框架
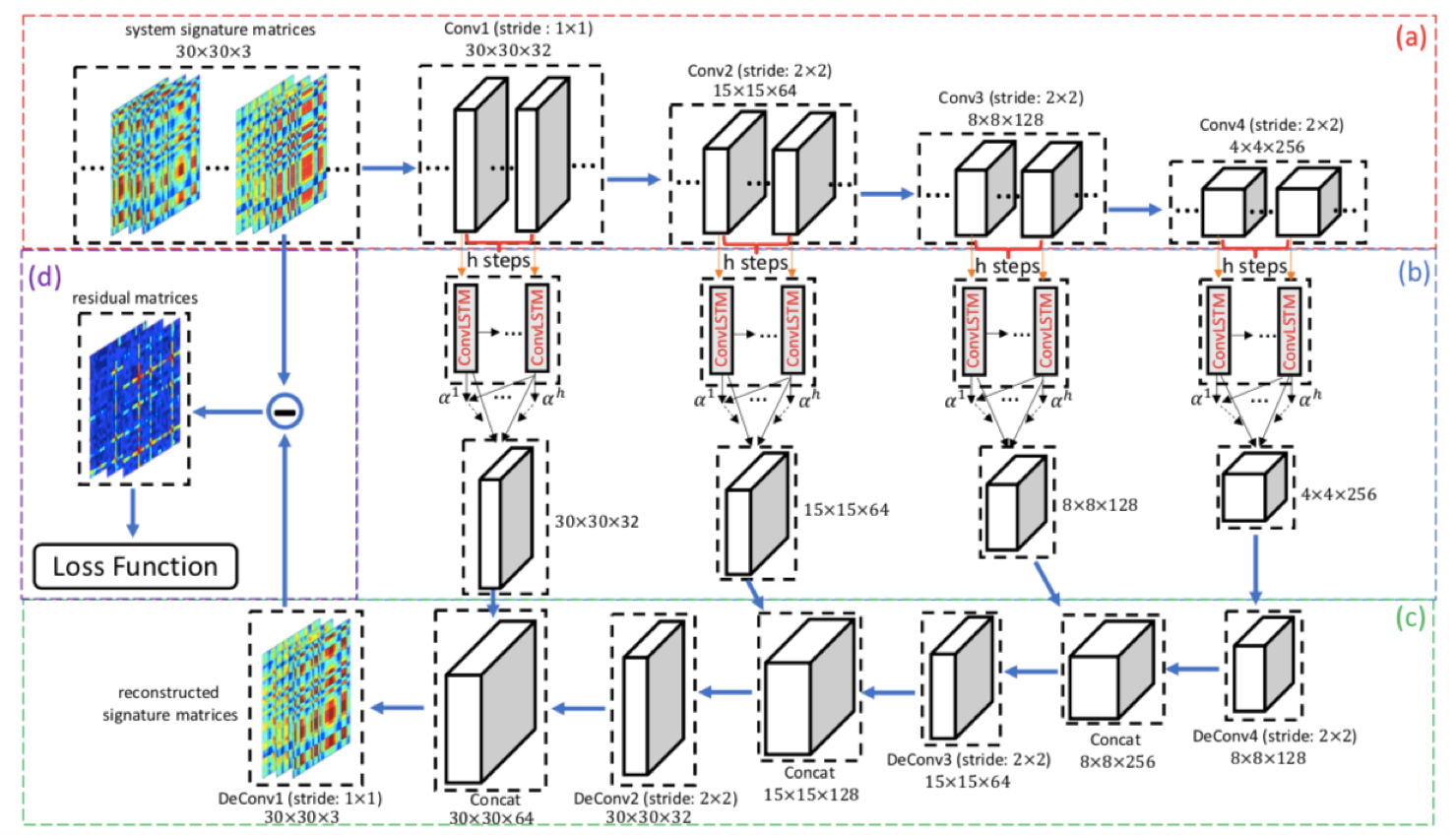
- 综合使用卷积层、Conv-LSTM 层和注意力机制构造 Encoder;
- 使用图像分割中常规的手段,在 Decoder 中将 Encoder 输出的特征图与上一级输出级联后再进行解卷积以逐级重建特征图,以此增加网络的拟合能力
关于LSTM和Conv-LSTM的对比:
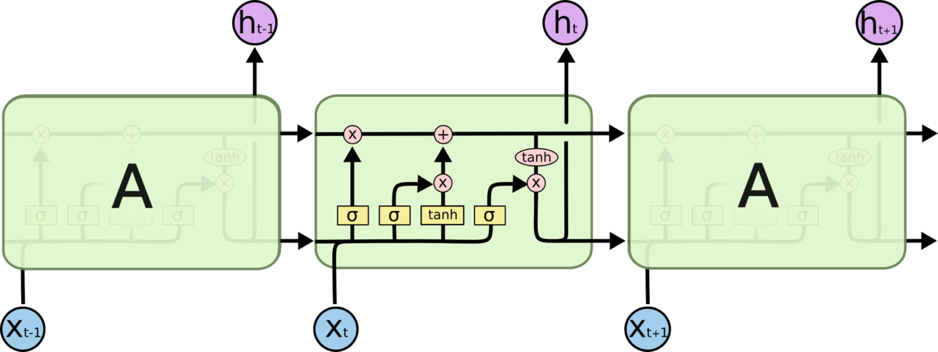
LSTM 是一种 RNN 特殊的类型,可以学习长期依赖信息,但能避免长期依赖问题。
Conv-LSTM的核心本质还是和LSTM一样,将上一层的输出作为下一层的输入。不同的地方在于ConvLSTM加入了卷积操作之后,不仅能够得到时序关系,还能够像卷积层一样提取空间特征。 这样Conv-LSTM就可以同时提取时间特征和空间特征(时空特征),并且状态与状态之间的切换也换成了卷积运算。
实验对比
实验数据:人造数据和真实数据(发电厂)
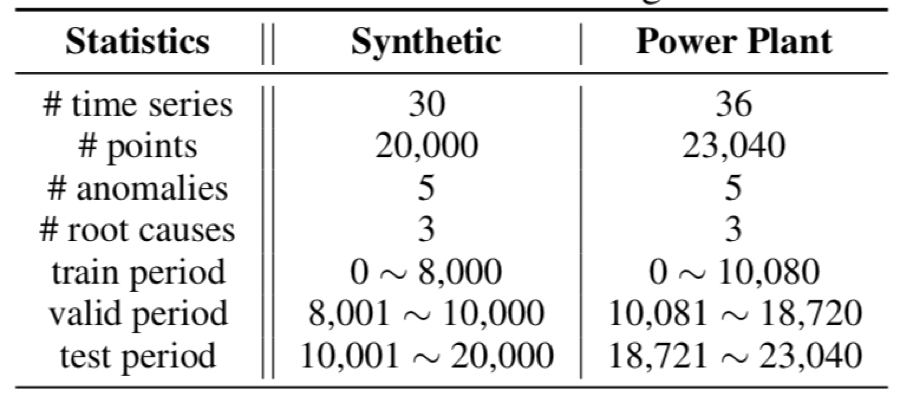
=====
人造数据的生成公式如下图:
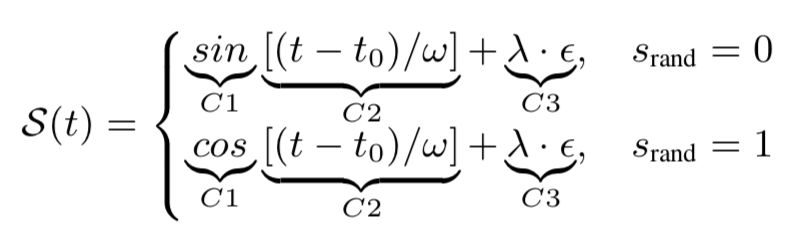
周期控制:t0取[50,100],w取[40,50];噪声控制:ε取N(0,1),λ = 0.3;
对比方法:
- 分类模型:OC-SVM
- 距离估计模型:DAGMM
- 预测模型:HA、ARMA、LSTM-ED
- MSCRED变体:
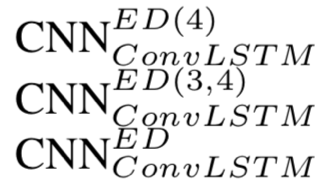
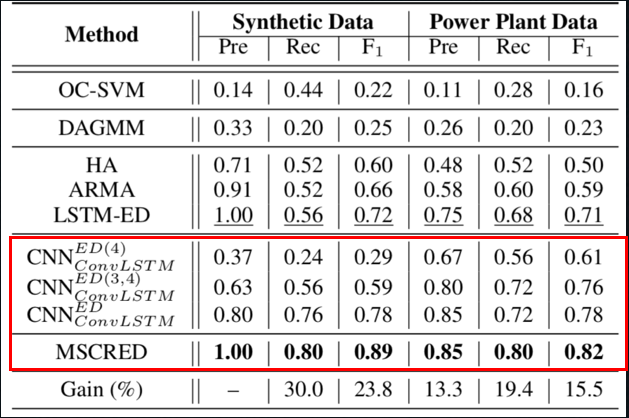
Q1:为什么该算法会比基准算法都好?
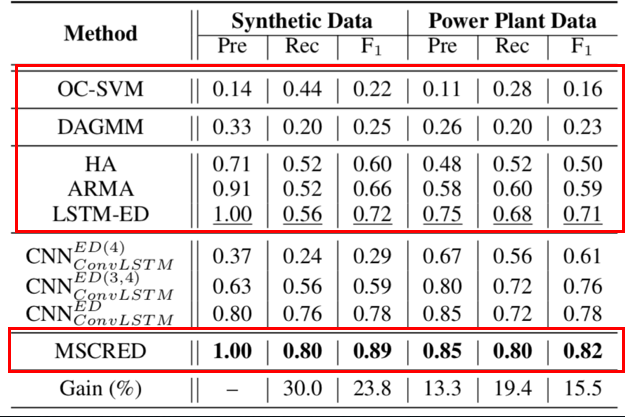
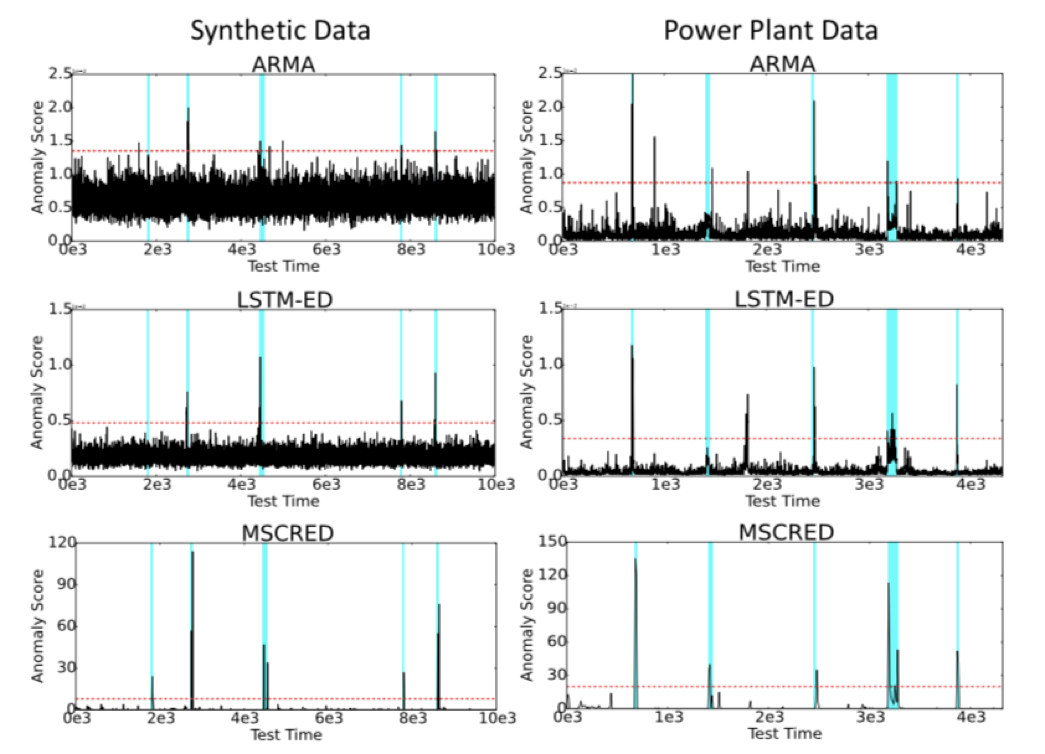
Q2:它的几个组成部分是怎么影响它的性能的?
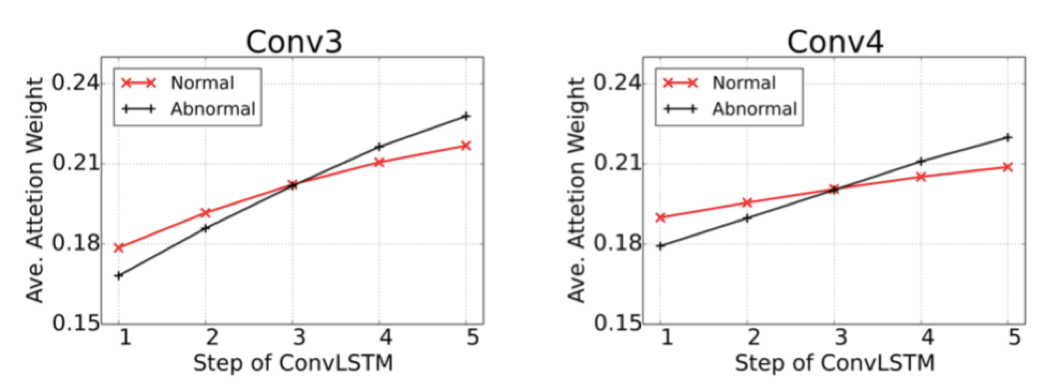
Q3:为什么它在根因分析上是有效的?
对比在根因分析方面效果很好的基准算法——LSTM-ED
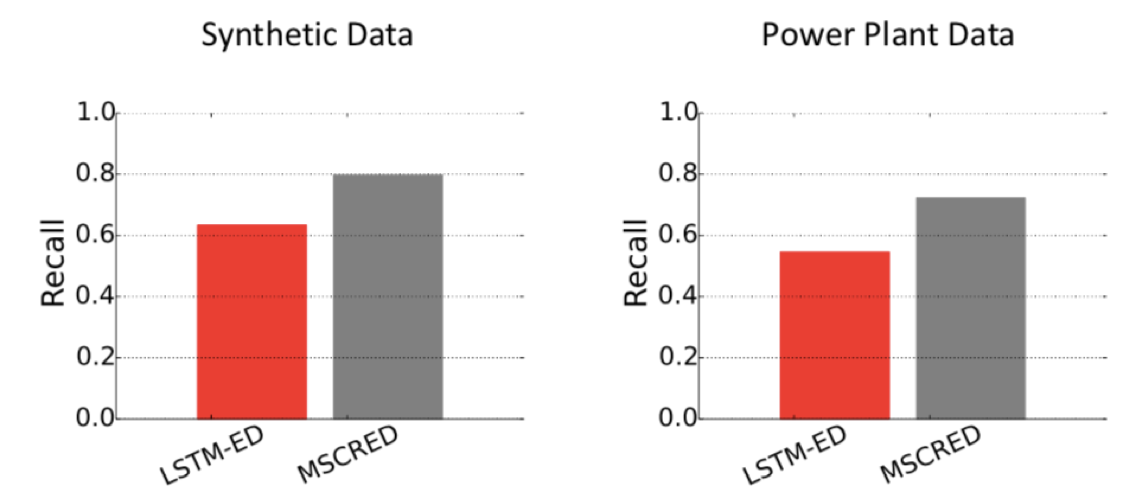
Q4:为什么它在异常严重程度上的解释是有效的?
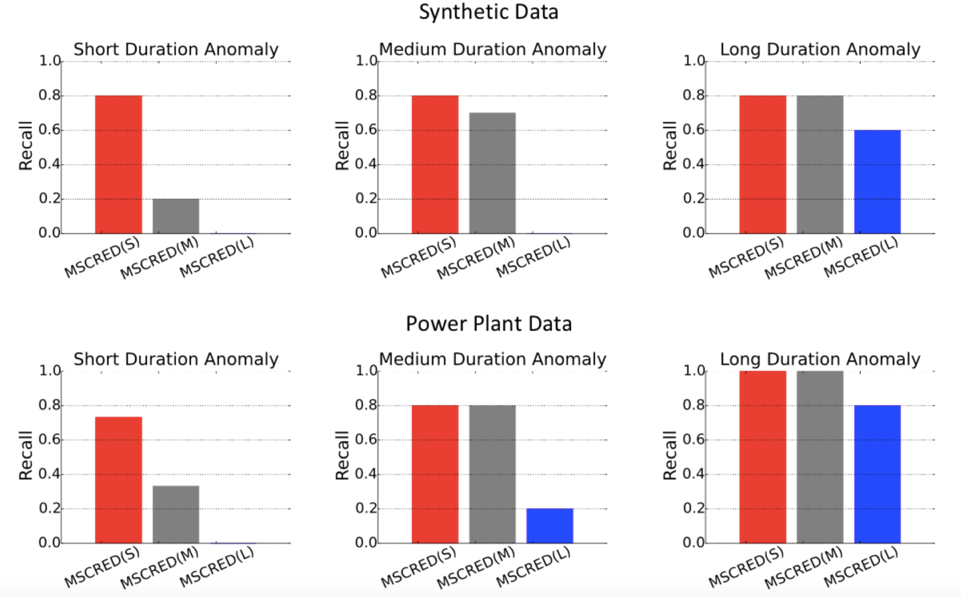
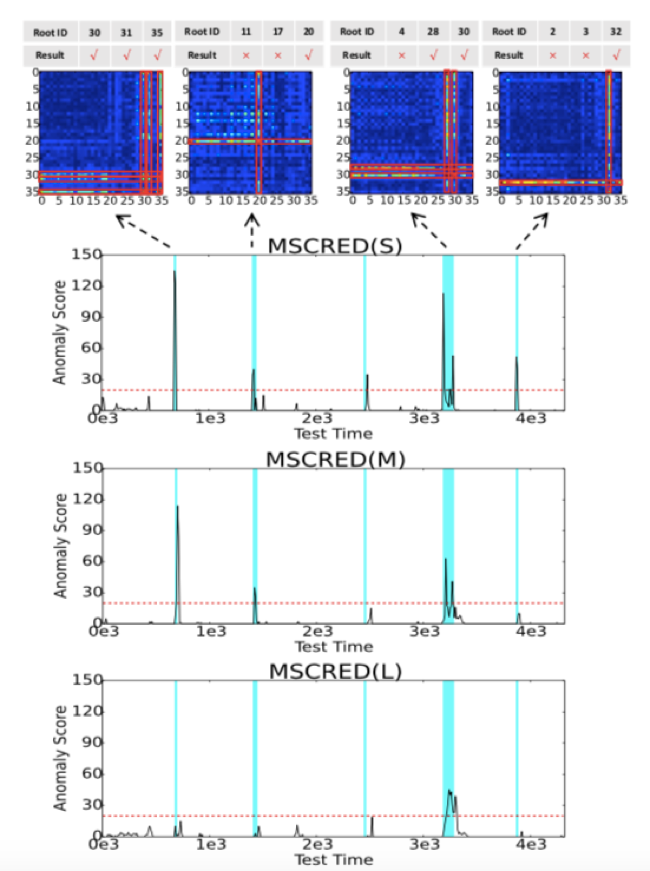
Q5:为什么它在应对噪音上是有效的?
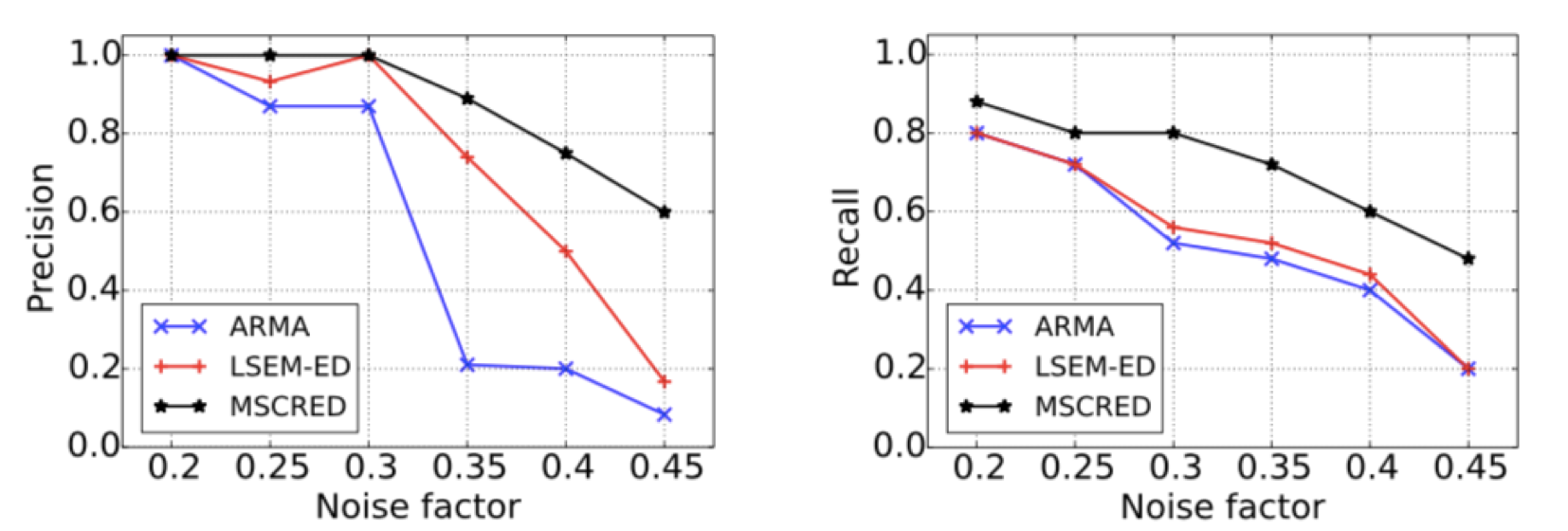
总结和后记
本文提出了现实环境中复杂系统的异常检测需要考虑到的两个点:
- 细粒度的警告,通过根因分析定位异常;
- 区分不同严重程度的异常,区别对待,减少资源浪费。
并基于这种考虑设计出了MSCRED模型算法。实验表明,该算法相比已有的算法,异常检测更精确,异常诊断结果更细粒度,同时对于噪声有更强的鲁棒性。
Github上有论文作者提供的项目代码,使用上会碰到很多bug(例如模型训练开始的次数没有重置为1,矩阵维度因为输入数据不同而造成计算存在偏差,tensflow版本的问题……),需要根据错误提示自行修改。
-END-