这是一篇清华大学NetMans实验室与阿里数据库团队联合发表在INFOCOM2019会议上的论文。
该论文介绍了一种基于划分分析的贝叶斯网络生成对抗训练方法,并将它和VAE模型结合,提出了新的针对复杂KPIs的非监督异常检测算法Buzz。
背景
为了保证Internet应用服务的可靠性,需要每时每刻对关键性能指标(KPI)进行实时监控。当KPI出现异常(如突然增加、突然下降和抖动)时,相关应用中会出现一些潜在的故障。为了降低故障造成的损失和解决故障的成本,必须及时准确地发现KPI中出现的故障。
目前,对于季节性平滑的服务级别KPIs(例如,每分钟的事务数)的异常检测已经得到了很好的解决,但是对于机器级别的复杂KPIs(例如,服务器每秒的I/O请求数)的异常检测问题却很少有人关注。下图展示了一些这类复杂KPIs示例:
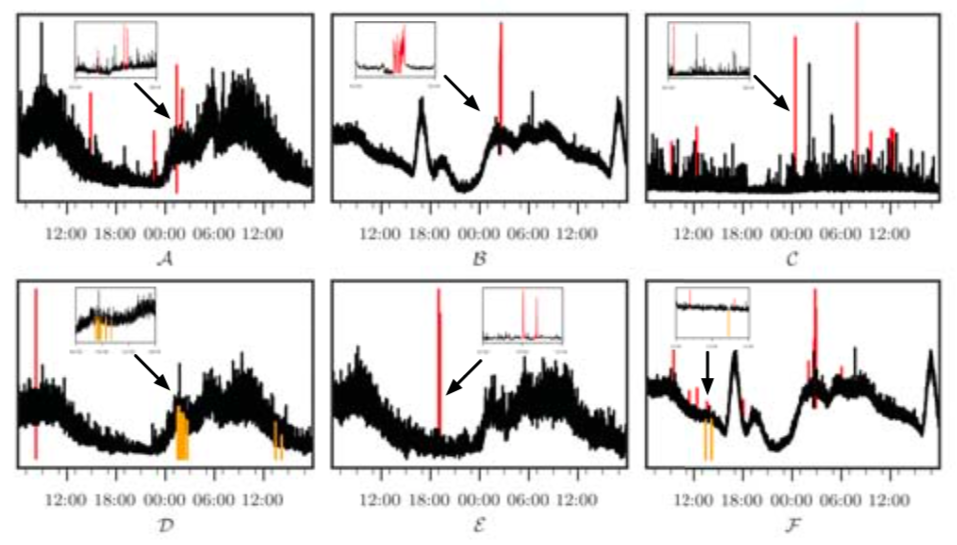
综上,本篇论文提出了一种针对复杂KPIs异常检测的新算法——Buzz。
相关工作
- 基于传统统计模型的方法
- 有监督集成学习方法,集合多种传统的异常检测方法(例如EGADS、Opprentice)
- 无监督异常检测方法(例如Donut、VAE)
算法模型
1.算法核心思想
- 为了使复杂KPIs的建模变得容易,使用了“分区发”(将数据空间划分为几个子空间,并计算每个子空间中的距离)。
- 计算距离时,使用生成分布和经验分布之间的Wasserstein距离(来自WGAN)。
- 在理论推导的基础上,提出了一种训练目标的初始形式,并将模型转化为贝叶斯网络。Buzz通过对抗性训练优化了VAE变异可能性的证据下限。
- 使用VAE作为生成模型来生成样本,并使用另一个神经网络作为判别模型来区分生成样本和真实样本。
- 为了保证对抗性训练的稳定性,我们采用了梯度惩罚技术(对WGAN的改进)
- 利用贝叶斯推理进行异常检测。
2.主要贡献
- 第一个将深度生成模型(Deep generative model)用于异常检测的无监督算法。将它用于一家全球顶级互联网公司的数据上,F-score高达0.92~0.99,明显优于现有方法。
- 首次将对抗训练方法和VAE结合,同时还用到了具有坚实理论推导和实验支持的划分分析方法。
- 初步提出了一种将基于划分分析的Wasserstein距离作为Buzz算法训练目标的想法,并给出了将模型转化为贝叶斯网络的理论推导。在贝叶斯网络和最优传输理论之间架起桥梁是一种新的思路。
KPI: 一个时间序列,可以表示为X={x1, x2, ……, XT},其中xT是与t∈{1,2,···,T}的时间索引t相对应的值。
异常检测中的KPI: 在给定W个数据点的最近历史记录的情况下,确定值xt是否为异常。如果xt是异常,则αt=1。异常检测算法通常计算条件概率P(αt=1 | x(t−W+1), ……, xt),而不是直接给出αt的值。
整个算法模型的结构设计如下:
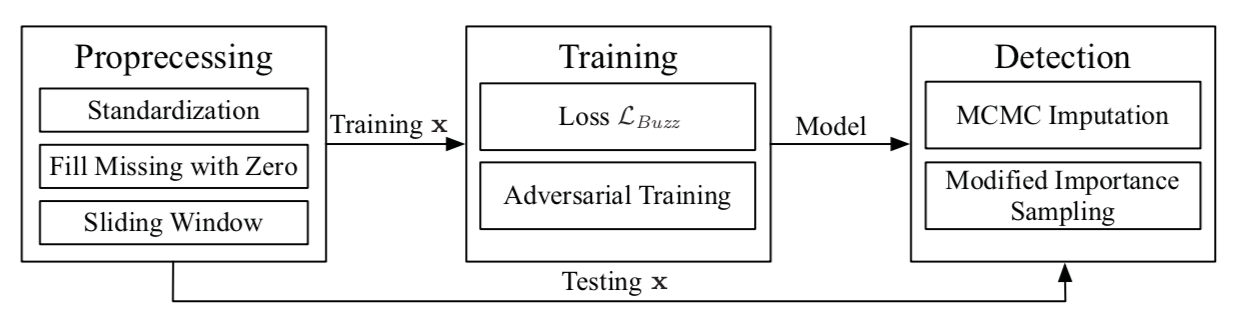
Buzz中有两个最重要的想法:Wasserstein距离和分区思想。当计算距离时,使用Wasserstein距离来度量生成分布和数据分布之间的距离(之后称作分布距离)。Wasserstein距离在WGAN中被认为能用于更鲁邦地来度量概率分布之间的距离。
分区思想是一种非常强大和通用的想法,经常用于分析学和测度论中。基础的想法类似于计算积分,这里将数据空间划分为很多个小区域,然后在每个小区域上计算分布距离。每个小区域上的分布距离是通过对抗训练的方法计算的,最后把每个小区域上计算得到的值计算取平均值,最后得到整体距离。
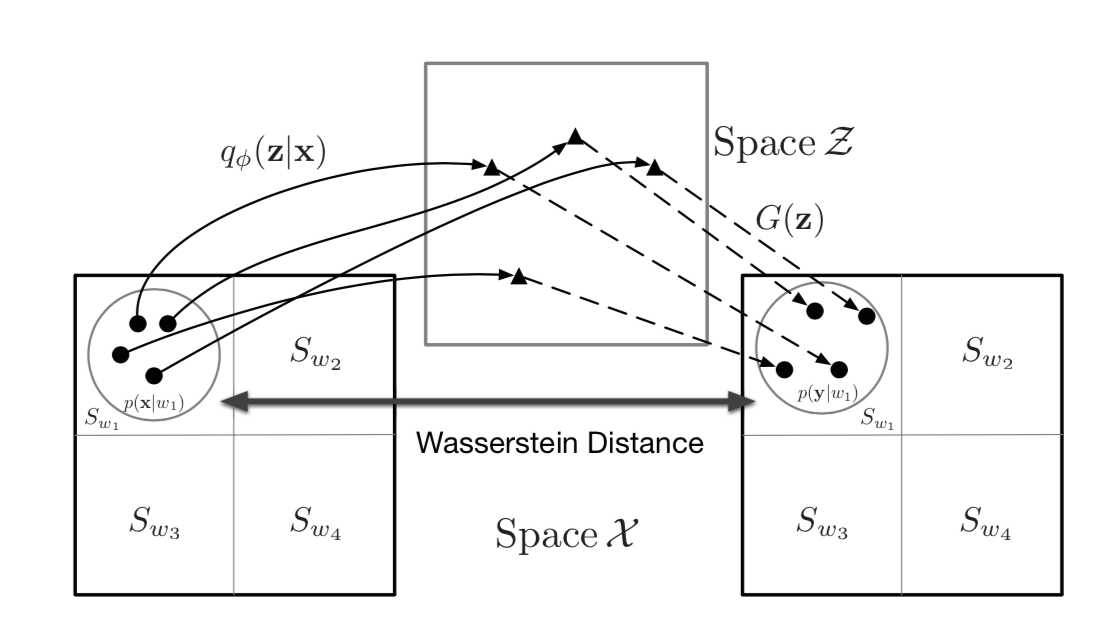
偶然的发现当分区越来越小时,整体距离会逼近VAE的某个特殊变种的证据似然下界中的重构项。分区想法扮演了连接WGAN的损失函数和VAE的桥梁。当分区从全局一块慢慢变得划分得越来越小时,我们实际上把损失函数一步步从WGAN变为了VAE。
模型的网络结构如下图所示:
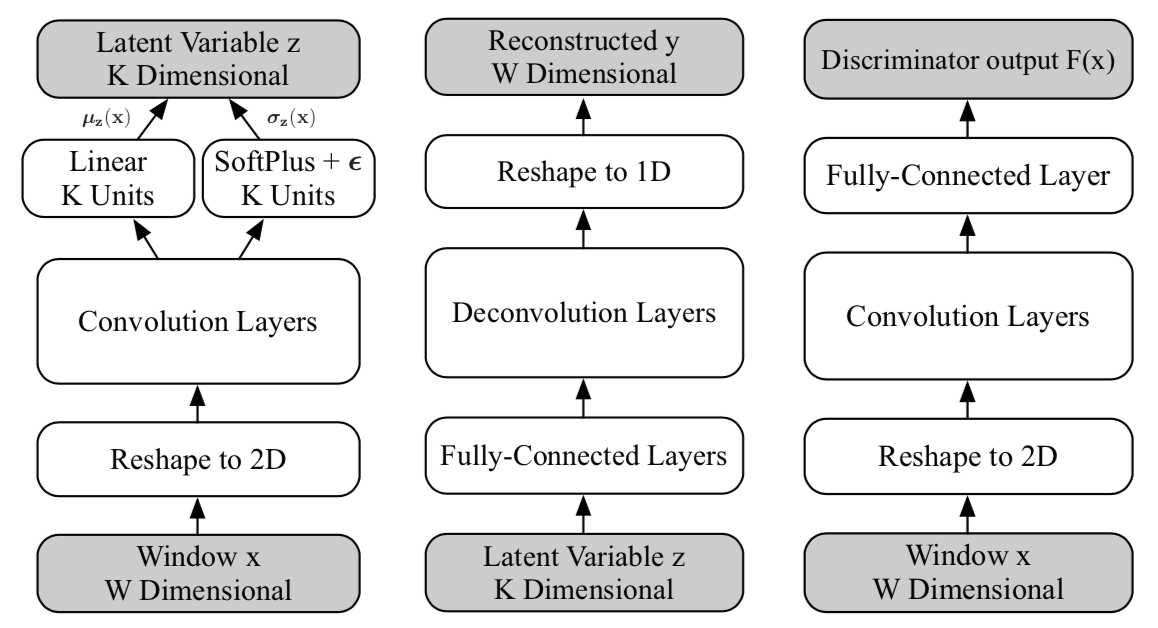
模型由3个子网络组成:变分网络,生成网络和判别网络。
Buzz中最重要的部分就是它的训练目标。这里为复杂KPIs专门提出了一个新颖的训练目标,用以解决在复杂的数据上难以对模型进行训练的问题。
| 具体的算法和推导可去阅读原论文。 |
实验对比
实验数据:
真实数据:使用一家大型互联网公司的11个维护良好的复杂KPIs指标,这些KPIs的时间跨度足以进行模型训练和结果的评估,所有的KPIs的监测间隔为10秒。
上表选取了A、B和C三个KPI指标进行观察,这些数据集的异常被完全标记。尽管其余8个KPI的标签没有那么完善,但它们代表了更多复杂KPI。
表中显示了数据集A、B、C的详细统计数据以及所有11个KPI的平均值。由于模型的输入是”窗口”,所以我们还计算了总窗口数和异常窗口数,即每个窗口至少包含一个异常点。每个KPI数据分为train组、valid组和test组,分别占数据集的56%、14%和30%。
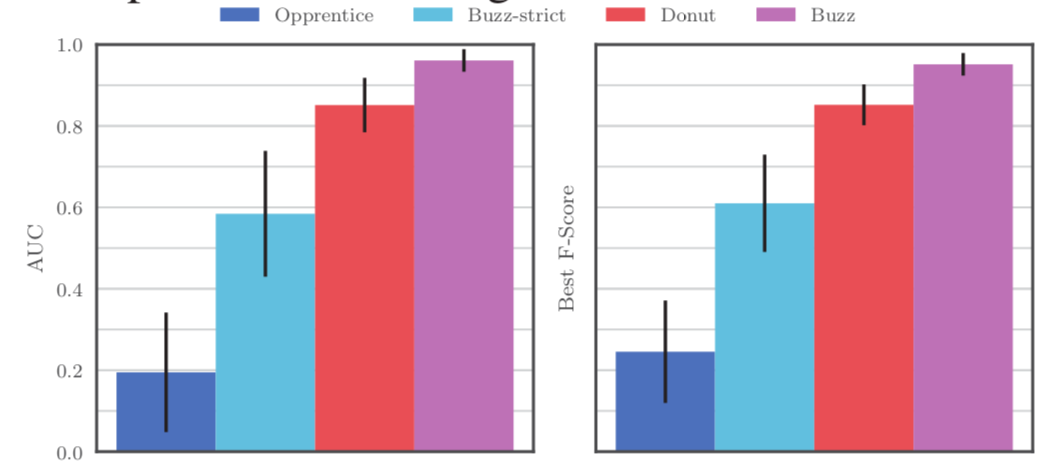
首先,实验比较了Buzz、Buzz-strict,Opprentice(最先进的有监督技术,超过了所有的传统统计模型)和Donut(最先进的无监督方法,在季节性平滑数据上超过了Opprentice)。每一个模型都在数据集A,B,C上运行了10次,在剩下的8个数据集上运行了一次。
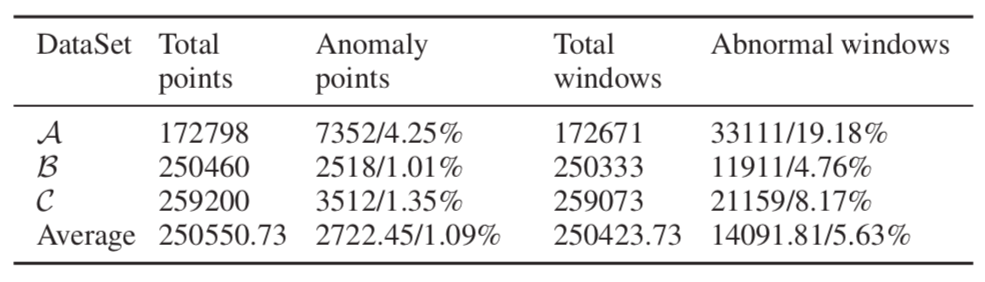
下图展示了使用AUC和最佳F-score来作为异常检测的评价指标:
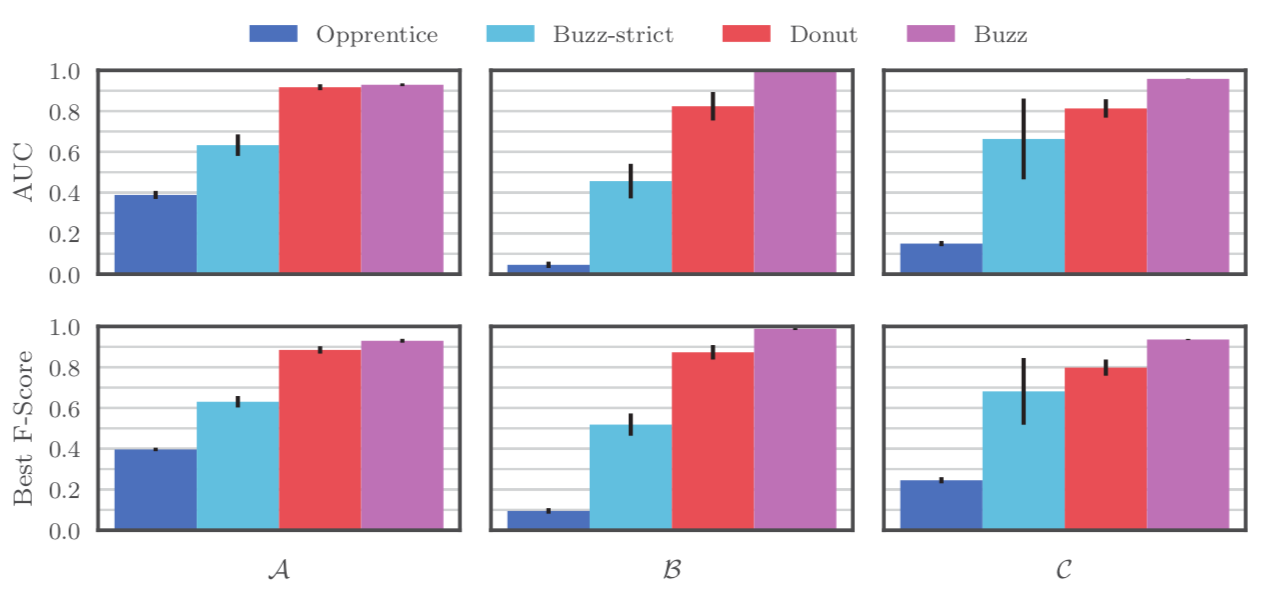
之后,展示Buzz算法在训练数据集(training set)和验证数据集(validation set)上的训练情况。结果表明,Buzz的对抗训练是稳定的,该算法的简单近似方法是有效的。如下图所示:
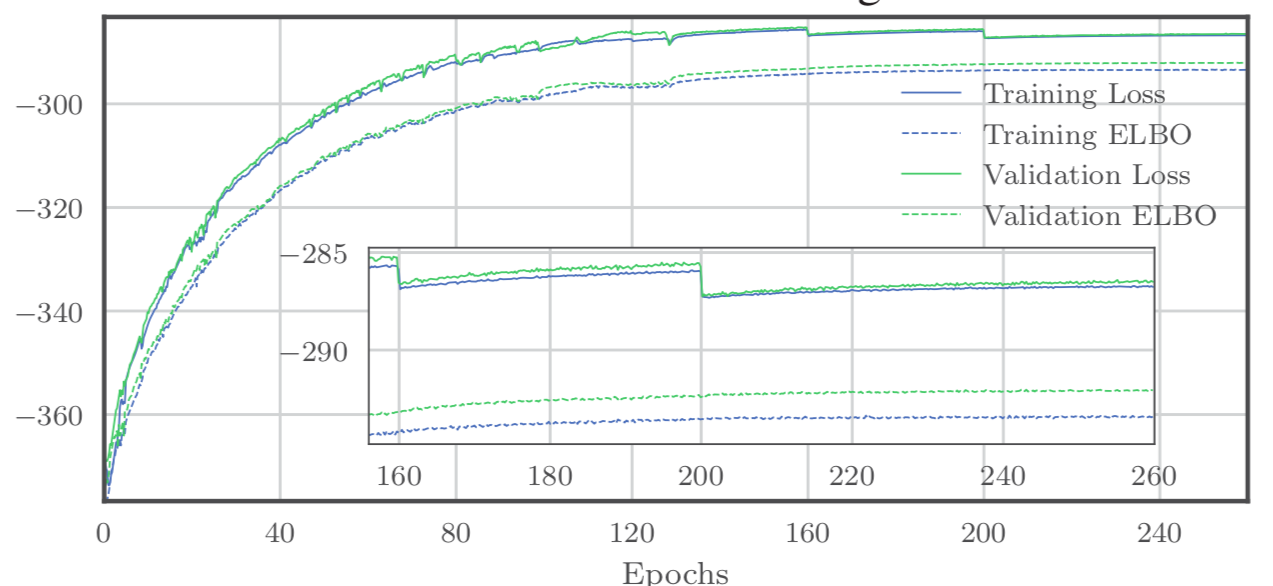
接着,比较Buzz和Donut中的KL项,它是对数概率似然和ELBO之间的差值,这表明Buzz的训练是良好而稳定的。如下图所示:
KL的值和方差越小,说明模型训练得越稳定。
ELBO,全称为 Evidence Lower Bound,即证据下界。这里的证据指数据或可观测变量的概率密度。
最后,比较了Opprentice,Buzz-strict,Dount和Buzz在11条KPIs上的总体性能。因为只有数据集A,B,C拥有完善的标注,而Opprentice是一个有监督算法,所以只在A,B,C上对它进行性能统计。结果表明Buzz在11条复杂KPIs上一致地表现很好。
总结和后记
- 提出的问题和研究点很有意义——复杂KPIs的异常检测,很少有人关注,也没有特别好的解决方案。
- 将生成对抗网络(本文用到的是WGAN)和VAE模型结合。之前有听其他同学提过可以将GAN用到异常检测中,现在又看到了这篇文章。
- 实验方法:之前看的MSCRED算法在实验部分用了人工数据和真实数据,但数据集只分出训练集和测试集。这篇文章只用到真实数据,并将数据集都分成了训练集、验证集和测试集。
| 在Github上找到了开源的代码。大概看了下项目,并没有像MSCRED那样有具体说明。待踩坑,踩完回来更新…… |
-END-